OCI Lakehouse DR Architecture with Automatic Switchover

It’s usually a good idea to have a second pair of shoes ready to wear in case of an unexpectedly heavy storm, so you can better handle the rain…
Introduction
In the first series of blog posts dedicated to the disaster recovery architecture for OCI Lakehouse, I described the disaster recovery solution for a real-time data warehouse, focusing on the configurations of the two main components in that scenario, namely Autonomous Data Warehouse (ADW) and OCI GoldenGate (please refer to Real Time Analytics DW DR Architecture Part I and Part II).
In this article, I go over how to set up the disaster recovery solution for the data server engine, the Autonomous Data Warehouse, and the integrated external storage, OCI Object Storage, which make up the core of persistence and data serving layer of this OCI Lakehouse architecture.
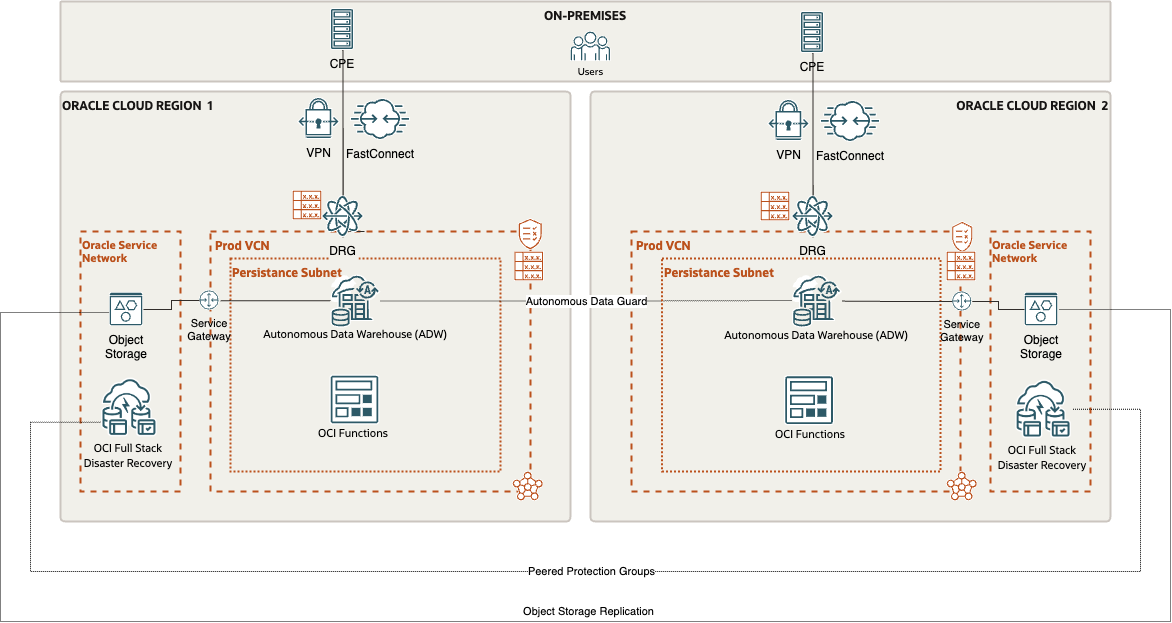
Oracle ADW is connected to an OCI Object Storage and can directly query data files ingested into Object Storage buckets.
To meet Disaster Recovery cross-Region criteria, another ADW (a Standby ADW) is automatically set-up and kept aligned in a different OCI Region (Region2) by enabling Autonomous Data Guard.
To provide a full disaster recovery solution, also the OCI Object Storage files are replicated in the OCI Region2 by creating an Object Storage replication policy.
In order to ensure that the solution works completely in the case of a region switchover, we lastly develop OCI Functions to handle a few more tasks that need to be completed.
This article shows how to handle all those configuration steps and how to use OCI Full Stack Disaster Recovery (FSDR) service to automate the entire DR switchover/failover process.
Single Region Initial Deployment
The initial configuration is a simple single region deployment (Region1, us-ashburn-1 OCI Region) with an Oracle ADW instance that can query external files (.csv files, in this case) stored in an Object Storage bucket.
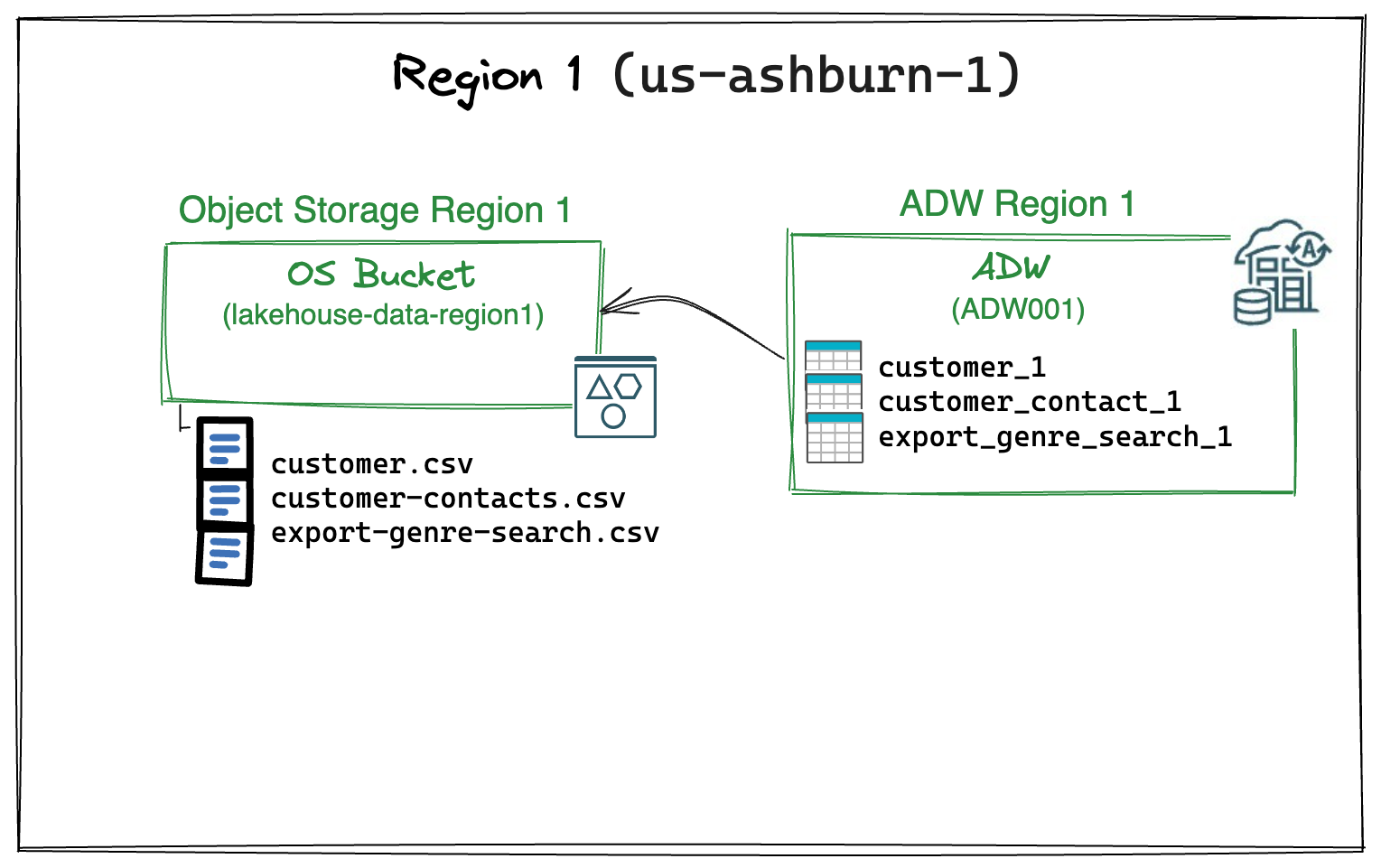
Region1 (us-ashburn-1) initial configuration
1) OCI Object Storage:
- Bucket Name: lakehouse-data-region1
-
CSV files stored in the bucket:
- customer.csv
- customer-contacts.csv
- export-genre-search.csv
2) Autonomous Data Warehouse deployment:
-
Instance Name: ADW001
-
External Tables: In the database schema LHUSER there are three external tables mapped on the correspondent Object Storage files:
- CUSTOMER_1
- CUSTOMER_CONTACT_1
- EXPORT_SEARCH_GENRE_1
The external table has been created using the CREATE_EXTERNAL_TABLE function of DBMS_CLOUD package. An example of creating an external table can be seen below.
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name =>'EXPORT_SEARCH_GENRE_1',
credential_name =>'OCI$RESOURCE_PRINCIPAL',
file_uri_list =>'https://objectstorage.us-ashburn-1.oraclecloud.com/n/frqap2zhtzbe/b/lakehouse-data-region1/o/export_search_genre.csv',
format => json_object('delimiter' value ',','quote' value '"','skipheaders' value 1)),
column_list => 'GENRE_ID INT, GENRE_NAME VARCHAR2(128)' );
END;
/
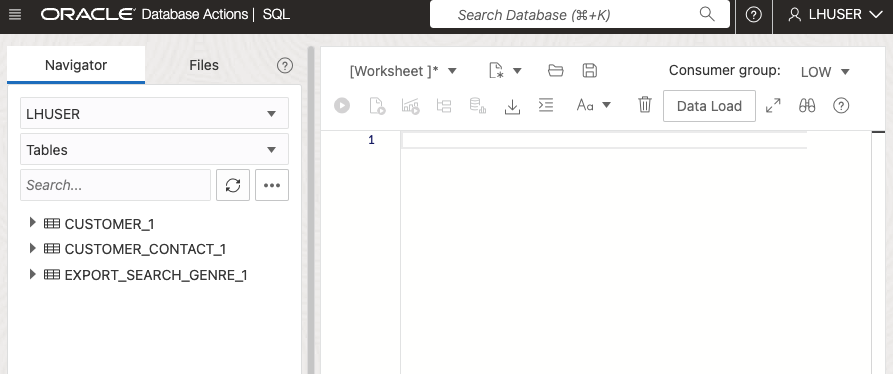
Initial ADW External Tables in Region1:
Enabling automated Lakehouse DR switchover
The following logical architecture shows the target configurations and components created for this Lakehouse cross-region disaster recovery sample architecture:
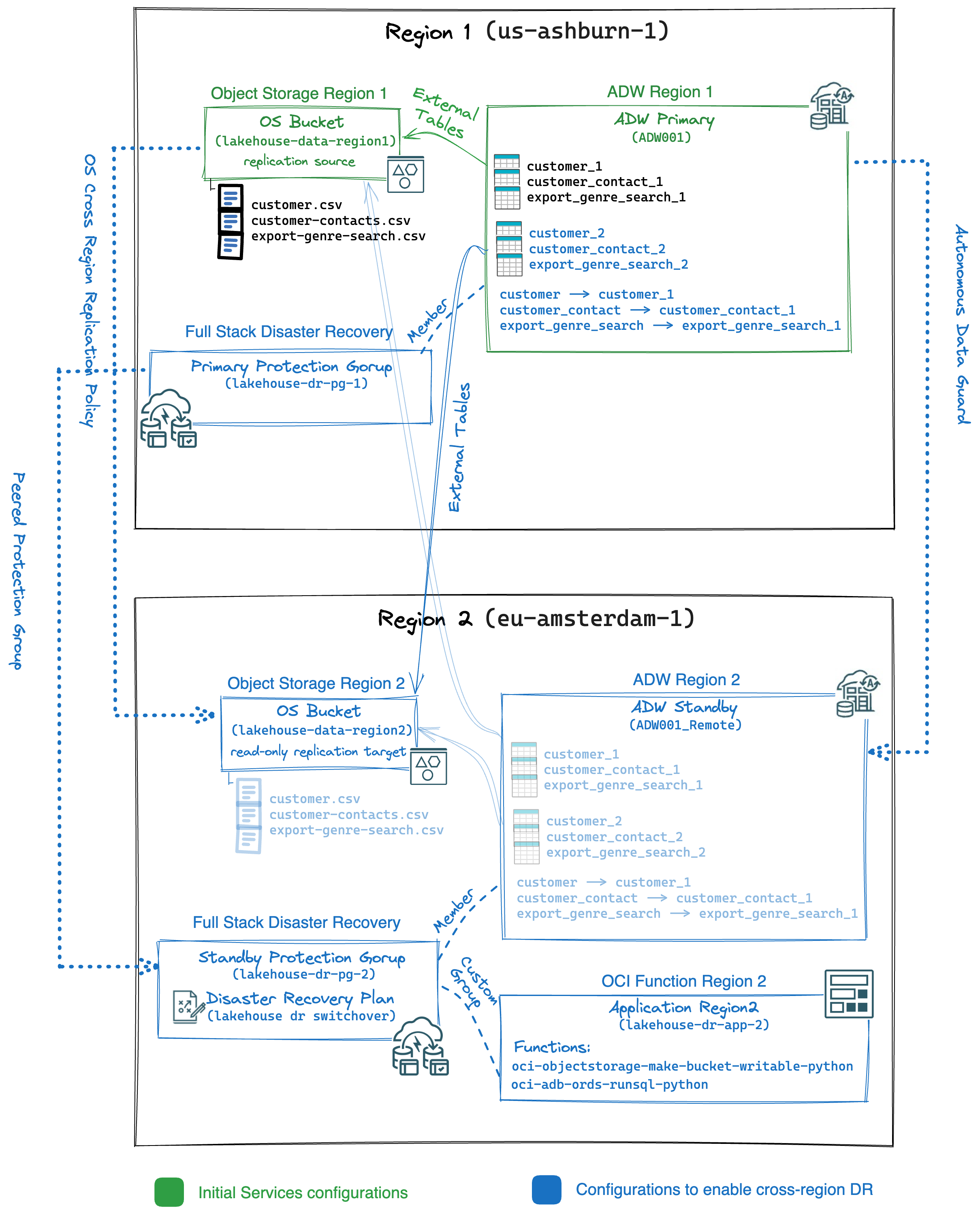
The core components of the architecture are Autonomous Data Warehouse and OCI Object Storage. First, we enable their replication capabilities (Object Storage Replication and Autonomous Data Guard) to provide the standby remote region (Region2) with a copy of the files of the Object Storage bucket and a standby instance of the Autonomous Data Warehouse.
For this scenario, it’s important to highlight a few details:
- Oracle ADW generates external tables that map specific bucket URIs in order to query files on Object Storage.
- The base Object Storage URI of the Region1 is different from the Object Storage base URI in the Region2.
- An Object Storage bucket that is target of a replication policy is a read-only bucket.
Then, when a failover or a switchover occurs we need to consider additional operations:
- Switch the mapping of the ADW external tables to the bucket that is addressable by the secondary Region’s Object Storage URI.
- Stop the Object Storage replication policy in target bucket on Region2.
We create OCI Functions to programmatically execute those task, since we don’t want to perform them manually.
But how to create a disaster recovery plan that can automatically carry out all necessary tasks in the appropriate order?
This is where Oracle Full Stack Disaster Recovery comes into play. With the help of this OCI service, you can create, test, implement, and monitor a disaster recovery plan that covers every step required to fully automate the cross-region switchover process. In this situation, it will orchestrate the swap of the ADW instances and the invocation of the OCI Functions in order to bring the solution’s functionality back to full capacity in the new region.
In details, this disaster recovery solution design includes these steps:
- Disaster Recovery configuration for OCI Object Storage:
- Enabling replication policy in the Object Storage bucket in Region1.
- Disaster Recovery configuration for ADW:
- Enabling Autonomous Data Guard for ADW in Region1.
- Creating ADW external tables mapped on the replicated files in the remote target Object Storage bucket.
- Create ADW synonyms based on the external tables.
- Creating ADW procedure to switch all the synonyms in a schema.
- OCI Functions to perform DR additional tasks:
- Creating OCI Function to invoke the ADW procedure.
- Creating OCI Function to stop replication policy in the target Object Storage bucket.
- OCI Full Stack Disaster Recovery Configurations:
- Creating a FSDR protection group in Region1, with the primary ADW as a member.
- Creating a FSDR protection group in Region2, with the standby ADW as a member.
- Peering the two FSDR protection groups.
- Creating a FSDR Plan with the built-in step (ADW switchover) followed by user-defined group that invoke the two OCI Functions.
Disaster Recovery configuration for OCI Object Storage
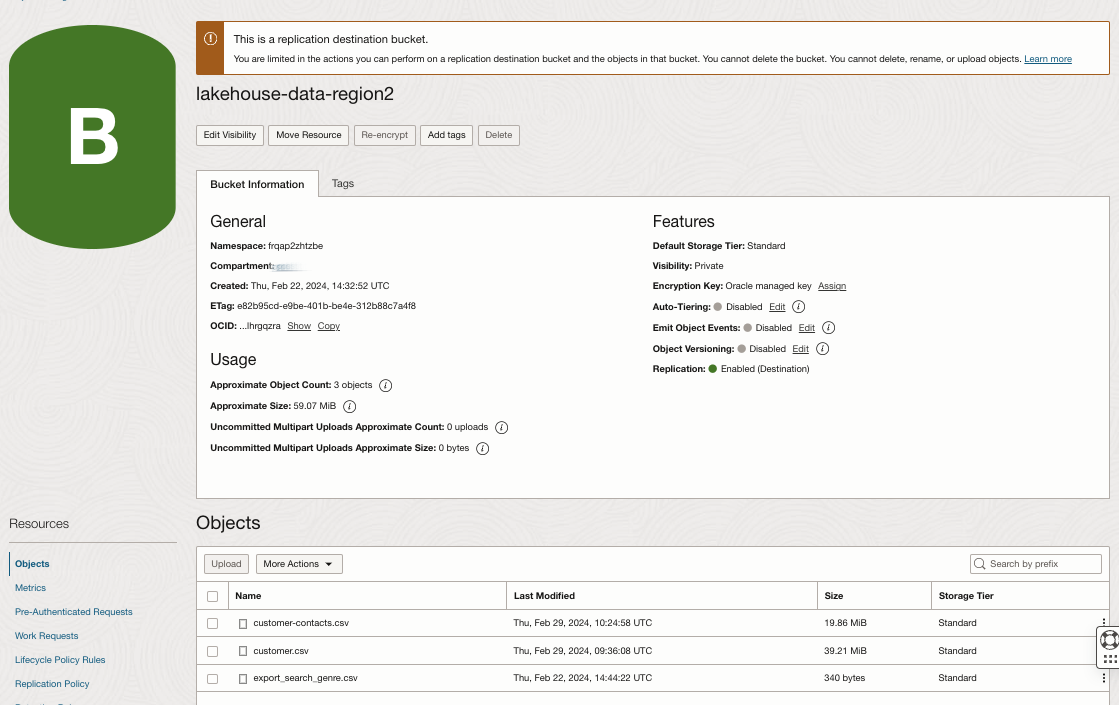
You need to automatically replicate the Object Storage files from the bucket in Region1 to the bucket in Region2 whenever a new file is stored in the bucket or an existing one is updated. Then you enable the Object Storage cross-region replication on the bucket lakehouse-data-region1 by configuring as a target the bucket lakehouse-data-region2 (previously created in Region2).
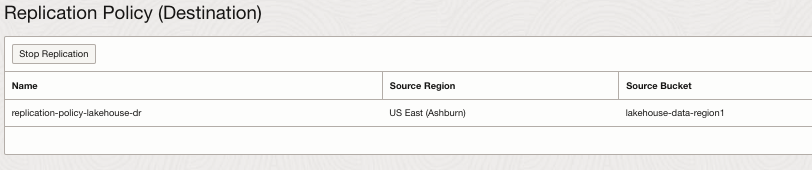
Object Storage replication policy on source bucket in Region1:

Target Object Storage bucket with replication policy in Region2:
Disaster Recovery configurations for ADW
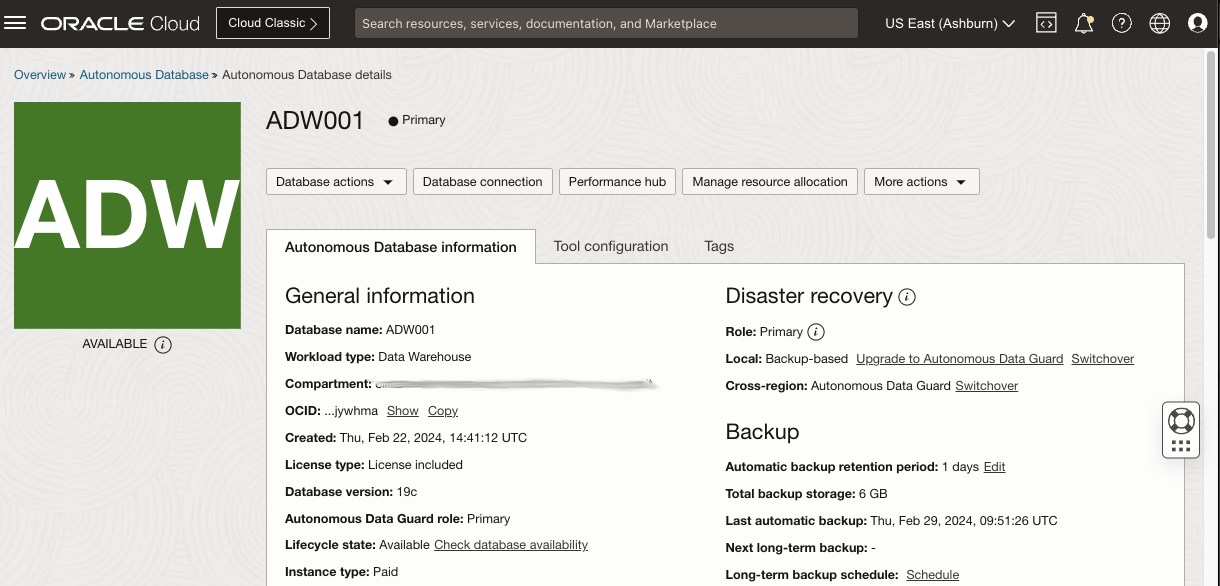
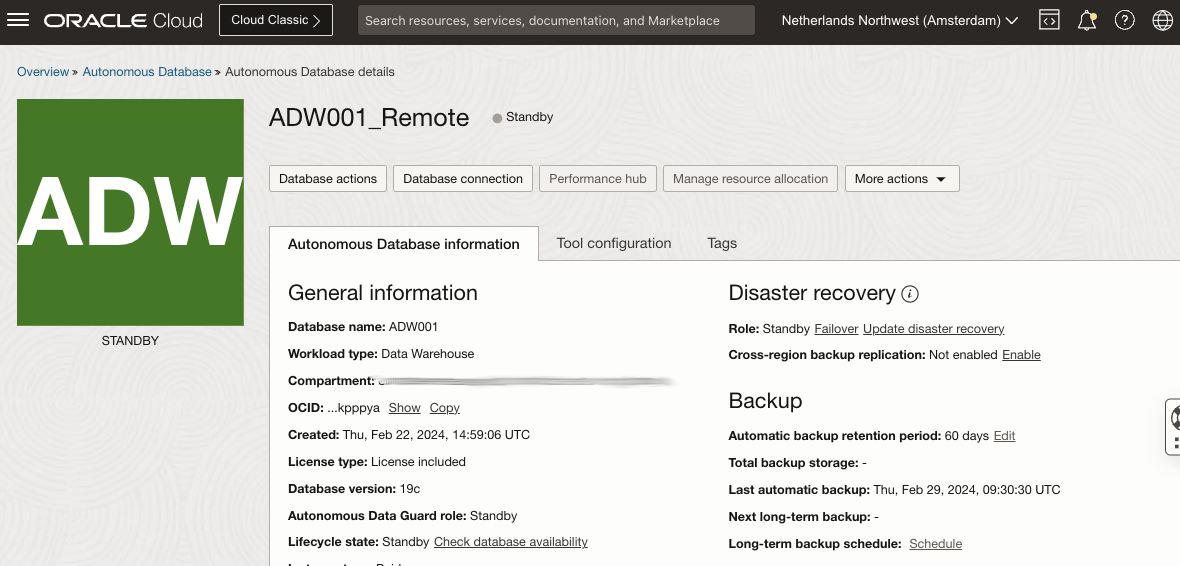
The DR configuration for ADW leverages Autonomous Data Guard. In the Autonomous Data Warehouse database in Region1 (ADW001), you enable a remote “Standby” database in Region2 (ADW001_Remote).
Autonomous Data Warehouse Primary instance in Region1:
Autonomous Data Warehouse Standby instance in Region2:
In order to promptly prepare ADW for a switchover/failover to Region1, you can create external tables mapped on the replicated files in the target replication bucket on Region2.
This is an example of the creation of an ADW external table mapped on the same file seen above, but replicated in Region2.
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name =>'EXPORT_SEARCH_GENRE_2',
credential_name =>'OCI$RESOURCE_PRINCIPAL',
file_uri_list =>'https://objectstorage.eu-amsterdam-1.oraclecloud.com/n/frqap2zhtzbe/b/lakehouse-data-region2/o/export_search_genre.csv',
format => json_object('delimiter' value ',','quote' value '"','skipheaders' value 1)),
column_list => 'GENRE_ID INT, GENRE_NAME VARCHAR2(128)' );
END;
/
At this point of the process, you have three couples of external tables, those with suffix _1 that are mapped on the source bucket in Region1 and those with suffix _2 mapped on the target replication bucket on Region2.
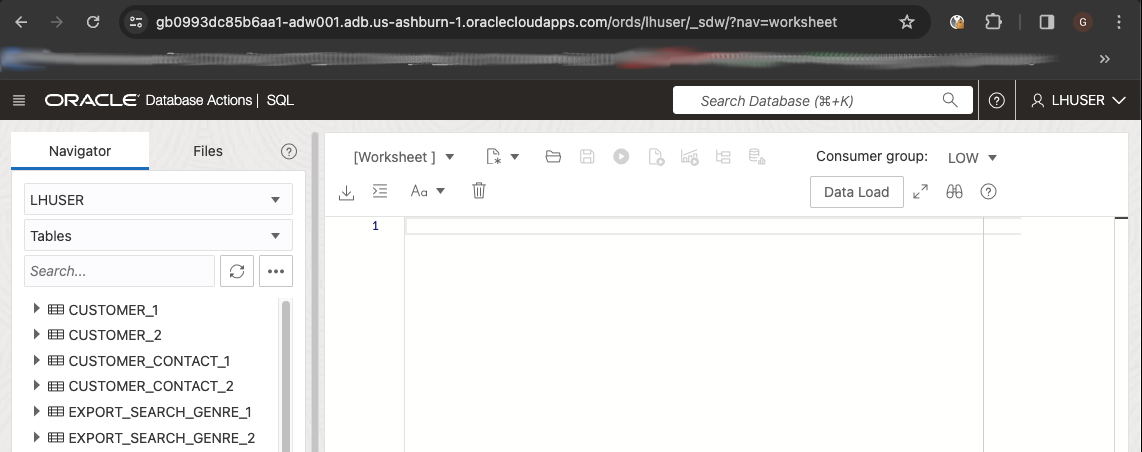
You can then define synonyms based on the external table to abstract the queries against those objects from the physical names of the external tables. Then, during a DR failover process, you just need to recreate the synonyms by switching their base tables from external tables mapped on files in Region1 to external tables mapped on files in Region2. This ensures that the queries against such ADW items will not require any change. You initially create the synonyms based on external tables with suffix _1, and you can keep those base tables as long as the workload is active in Region1. Following the naming convention used in this example, you can create the synonym with same name of the base table without the suffix.
For example:
CREATE OR REPLACE SYNONYM EXPORT_SEARCH_GENRE FOR EXPORT_SEARCH_GENRE_1;
You create the synonyms for all the external tables:
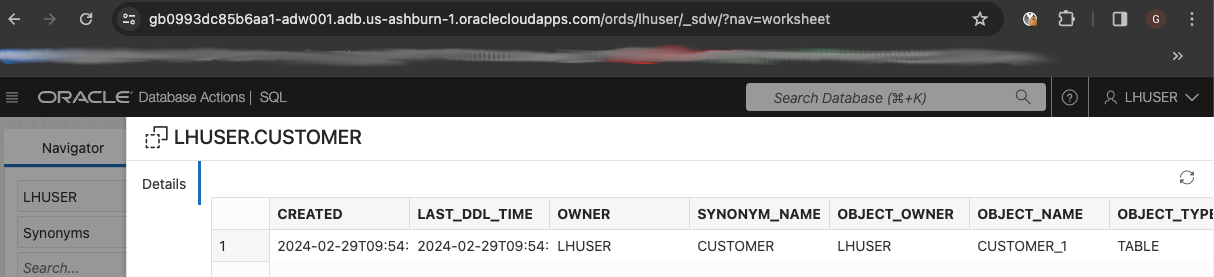
This is a sample of synonym metadata that shows the base table in Region1:
Finally, on ADW, you need a procedure to automatically replace all the synonyms present in a schema. The procedure will retrieve all the synonyms metadata, and execute a sql statement for each synonym to replace the base table. In this case you have three synonyms and if you need to switch the synonyms after a failover from Region1 to Region2 you need to execute the following statements on ADW:
CREATE OR REPLACE SYNONYM CUSTOMER FOR CUSTOMER_2;
CREATE OR REPLACE SYNONYM CUSTOMER_CONTACT FOR CUSTOMER_CONTACT_2;
CREATE OR REPLACE SYNONYM EXPORT_SEARCH_GENRE FOR EXPORT_SEARCH_GENRE_2;
As example, I created the following procedure SWAP_SYNONYMS that reads all the synonyms in the schema supplied as SYN_SCHEMA parameter and modify their base tables suffix with the value of the parameter REGION_NUM.
CREATE OR REPLACE PROCEDURE LHUSER.SWAP_SYNONYMS
(
REGION_NUM VARCHAR2,
SYN_SCHEMA VARCHAR2
)
AUTHID CURRENT_USER IS
TYPE values_t IS TABLE OF VARCHAR2(32767);
SQLstring values_t;
BEGIN
EXECUTE IMMEDIATE
'SELECT ''CREATE OR REPLACE SYNONYM ''|| SUBSTR(TABLE_NAME,1,length(TABLE_NAME)-2)|| '' for '' || SUBSTR(TABLE_NAME, 1, LENGTH(TABLE_NAME)-1)||' || REGION_NUM || ' FROM ALL_SYNONYMS where owner = '''|| SYN_SCHEMA || ''''
BULK COLLECT INTO SQLstring;
FOR indx IN 1 .. SQLstring.COUNT
LOOP
DBMS_OUTPUT.put_line (SQLstring (indx));
EXECUTE IMMEDIATE SQLstring (indx);
END LOOP;
END SWAP_SYNONYMS;
/
OCI Functions to perform DR additional tasks
In this DR solution, you have to define a DR user-defined group with the steps that allow for a full recovery plan during switchover/failover operations to Region1:
- Stop the Object Storage replication in the bucket that is the replication target. This allows you to use it as a normal bucket for both reading and writing operations.
- Switch the synonyms from to the base tables mapped on the files stored in the Region1 source bucket, to the base tables mapped on the files stored in the Region2 target bucket.
With OCI Full Stack Disaster Recovery, you have three different choices for configuring the user-defined steps:
- Run Object Storage script
- Run local script
- Invoke an OCI Function
In this example, I deployed two OCI Functions in an OCI Function application in Region2 (named lakehouse-dr-app)
As examples, the two function I used are listed below.
Function oci-objectstorage-make-bucket-writable-python
The first OCI Function leverages OCI API Python SDK. The following Python sample code uses the make_bucket_writable API to stop the replication policy of a bucket (the bucket name must be supplied as parameter value):
#
# oci-objectstorage-make-bucket-writable-python version 1.0
#
import io
import os
import json
import sys
from fdk import response
import oci.object_storage
def handler(ctx, data: io.BytesIO=None):
try:
body = json.loads(data.getvalue())
bucketName = body["bucketName"]
except Exception:
error = 'Input a JSON object in the format: \'{"bucketName": ""}}\' '
raise Exception(error)
resp = make_bucket_writable(bucketName)
return response.Response(
ctx,
response_data=json.dumps(resp),
headers={"Content-Type": "application/json"}
)
def make_bucket_writable(bucketName):
signer = oci.auth.signers.get_resource_principals_signer()
client = oci.object_storage.ObjectStorageClient(config={}, signer=signer)
namespace = client.get_namespace().data
print("Making bucket writable...", flush=True)
object = client.make_bucket_writable(namespace, bucketName)
print(object.headers)
Function oci-adb-ords-runsql-python
The second OCI Function leverages the ADW Rest Data Service sql-endpoint to run a sql statement provided in the sql parameter value. In this case the sql statement will be the execution of the PL-SQL procedure that switch the base tables of the synonyms.
import io
import json
import requests
from fdk import response
def ords_run_sql(ordsbaseurl, dbschema, dbpwd, sql):
dbsqlurl = ordsbaseurl + dbschema + '/_/sql'
headers = {"Content-Type": "application/sql"}
auth=(dbschema, dbpwd)
r = requests.post(dbsqlurl, auth=auth, headers=headers, data=sql)
result = {}
try:
r_json = json.loads(r.text)
for item in r_json["items"]:
result["sql_statement"] = item["statementText"]
if "errorDetails" in item:
result["error"] = item["errorDetails"]
elif "resultSet" in item:
result["results"] = item["resultSet"]["items"]
elif 'SQL procedure successfully' in r.text:
result["response"]= item["response"]
else:
raise ValueError("No Error nor results found.")
except ValueError:
print(r.text, flush=True)
raise
return result
def handler(ctx, data: io.BytesIO=None):
ordsbaseurl = dbuser = dbpwdcypher = dbpwd = sql = ""
try:
cfg = ctx.Config()
ordsbaseurl = cfg["ords-base-url"]
dbschema = cfg["db-schema"]
dbpwdcypher = cfg["db-pwd-cypher"]
dbpwd = dbpwdcypher # The decryption of the db password using OCI KMS would have to be done, however it is addressed here
except Exception:
print('Missing function parameters: ords-base-url, db-user and db-pwd', flush=True)
raise
try:
body = json.loads(data.getvalue())
sql = body["sql"]
except Exception:
print('The data to pass to this function is a JSON object with the format: \'{"sql": ""}\' ', flush=True)
raise
result = ords_run_sql(ordsbaseurl, dbschema, dbpwd, sql)
return response.Response(
ctx,
response_data=json.dumps(result),
headers={"Content-Type": "application/json"}
)
Note: This and many other OCI Function samples are available in the Oracle Samples Github repository. The function used in this example is documented here. The only modification that I made was to properly handle the text result of a procedure call.
Full Stack Disaster Recovery Configuration
To automate a DR switchover with OCI FSDR you create (and peer) DR Protection Groups (Primary and Standby), and a DR plan with built-in and user-defined groups. You can define different types of DR Plan to test and execute DR procedures (see DR Plans documentation for details). For the purpose of this article I created a switchover plan. In this case, you need to:
-
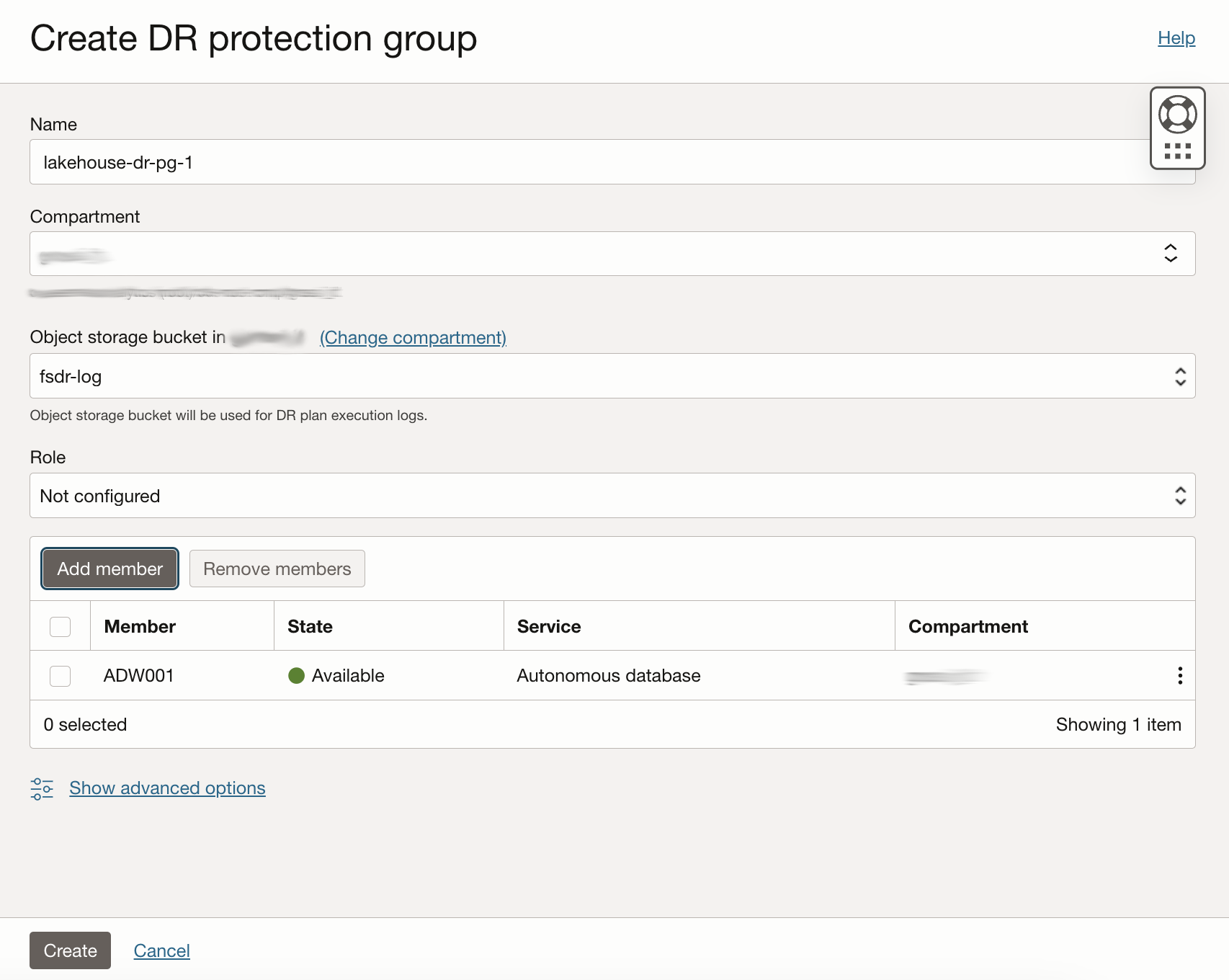
Create a DR Protection Group in Region1 (lakehouse-dr-pg-1) and add the ADW Primary instance (ADW001) as member, with Role Not Configured (you cannot assign a Role until you have created another DR Protection Group).
-
Create a DR Protection Group in Region2 (lakehouse-dr-pg-2), add the ADW Standby instance (ADW001_Remote) as member, peer this group to the lakehouse-dr-pg-1 created in Region1, and assign it the Standby role (this will automatically assign the Primary role to the DR Protection Group created in Region1).
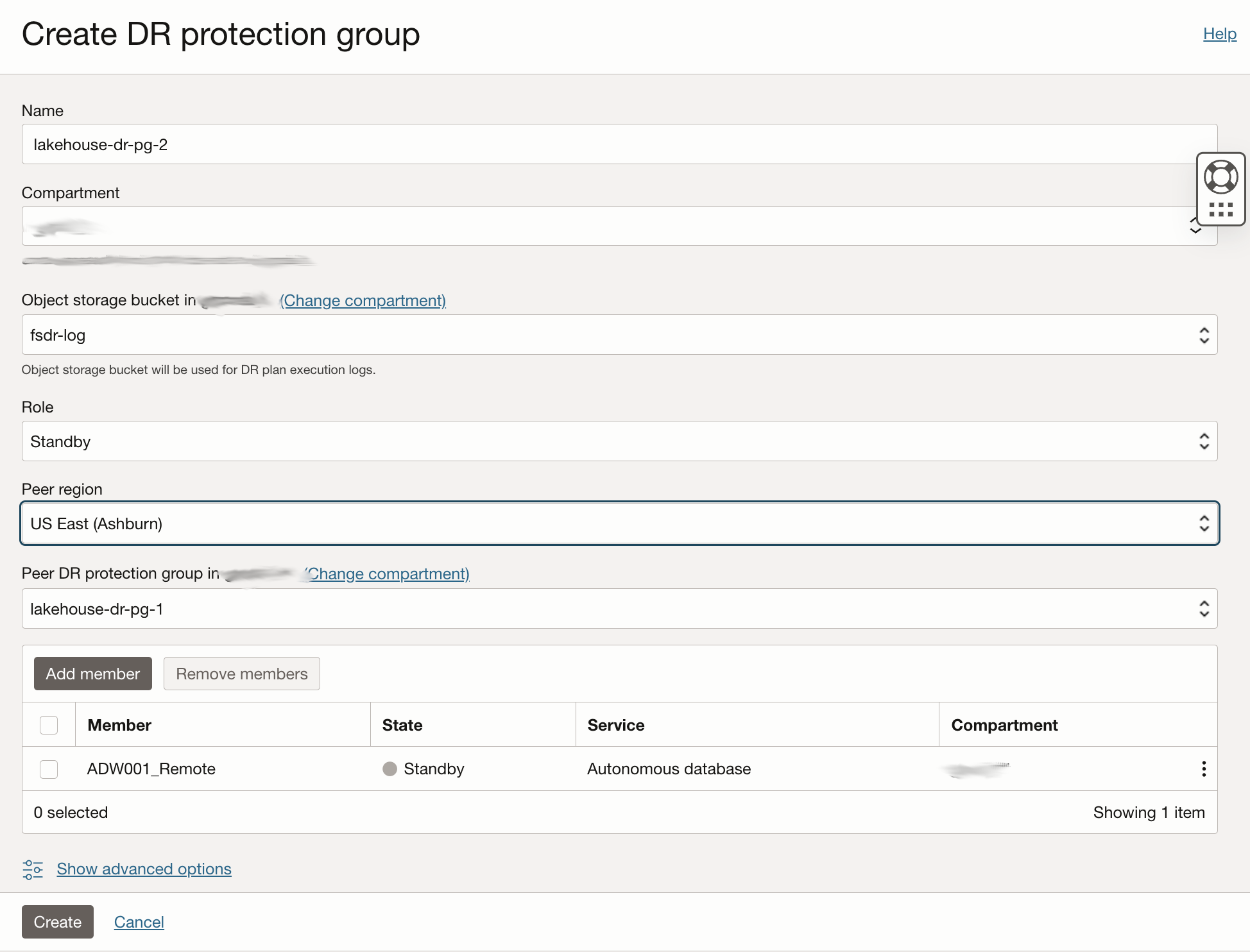
-
Create a DR Plan for DR Protection Group in Region2 (DR Plan can only be created at the Standby DR Protection Group).
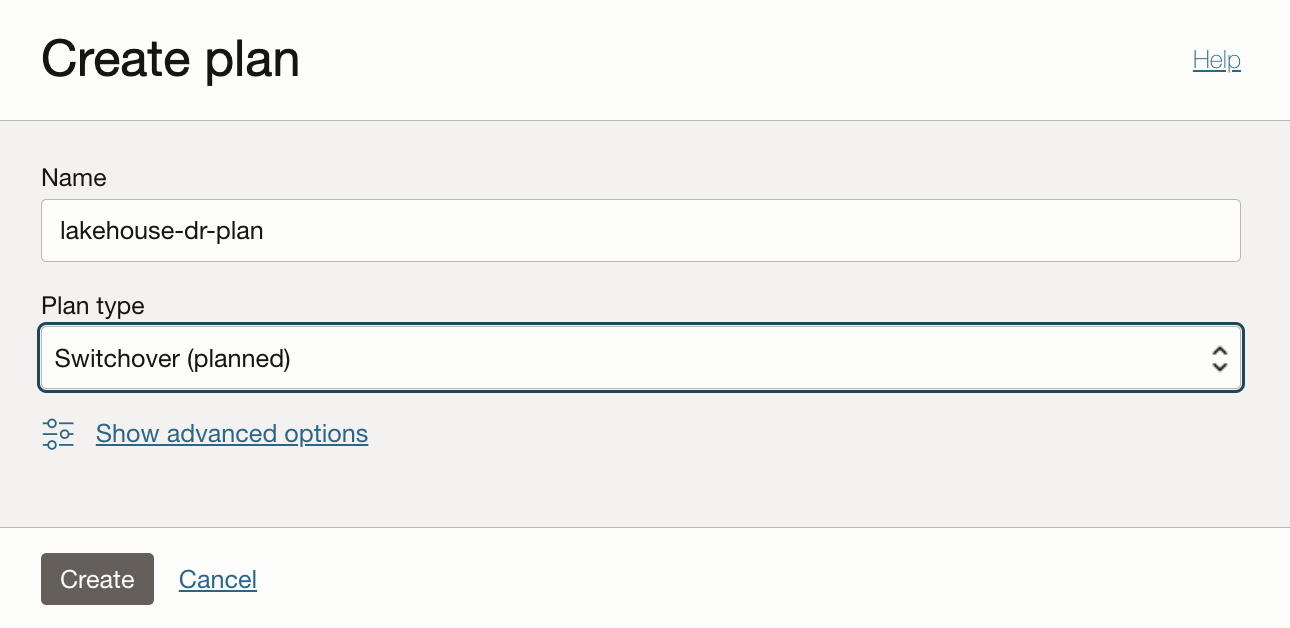
Once created, the DR Plan comes with two Built-in Plan Groups:
- Prechecks: Prechecks built-in group perform a set of checks to validate that a DR Plan is compliant with the members and configuration of the DR Protection Groups with which the DR Plan is associated. Prechecks are used to perform ongoing DR Plan validation (DR readiness checks) to ensure that the DR Plan (DR workflow) stays aligned with the topology it protects
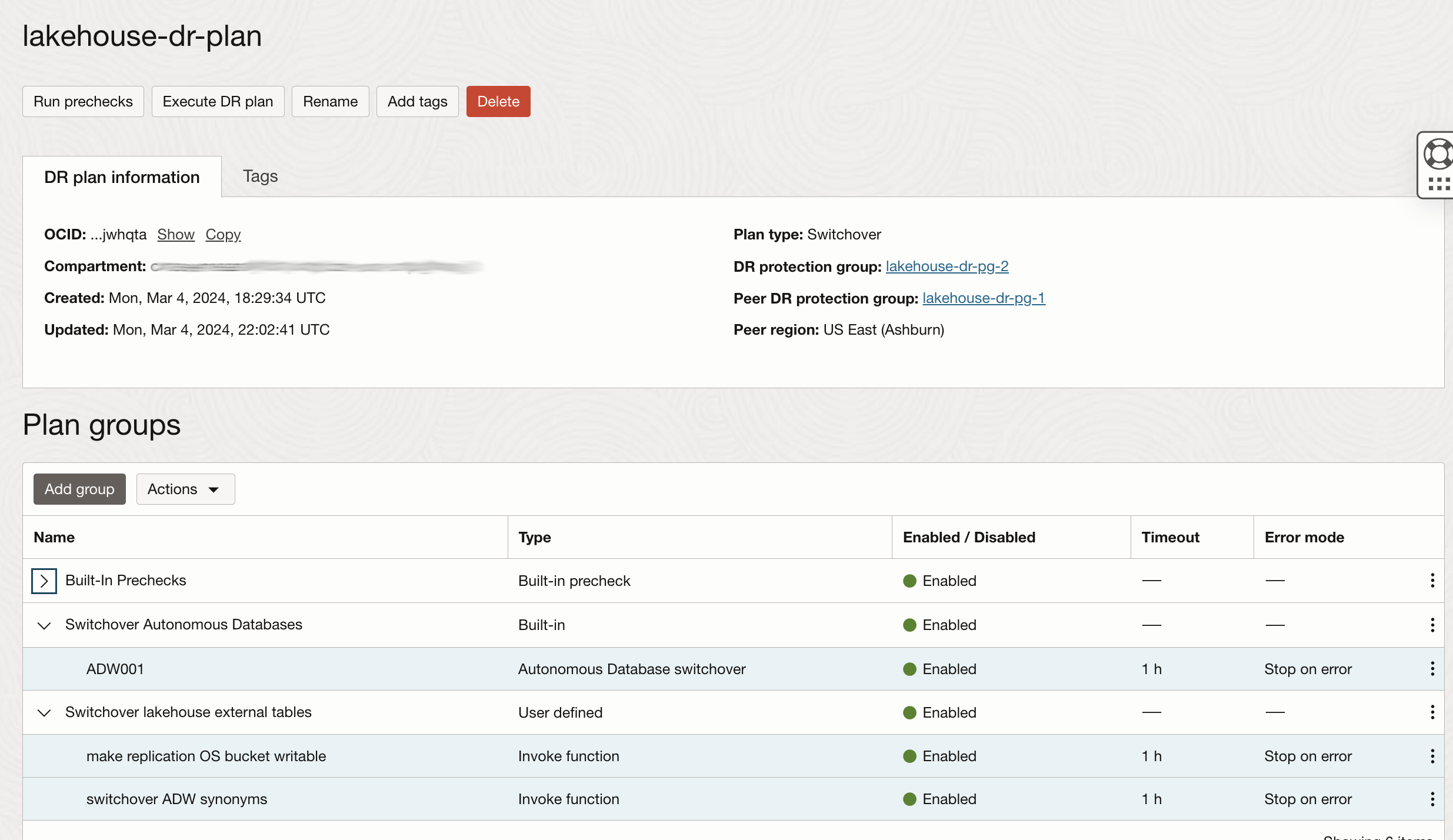
- Switchover Autonomous Databases: step for ADW (ADW001) switchover generated automatically by Full Stack DR when DR Plan has been created.
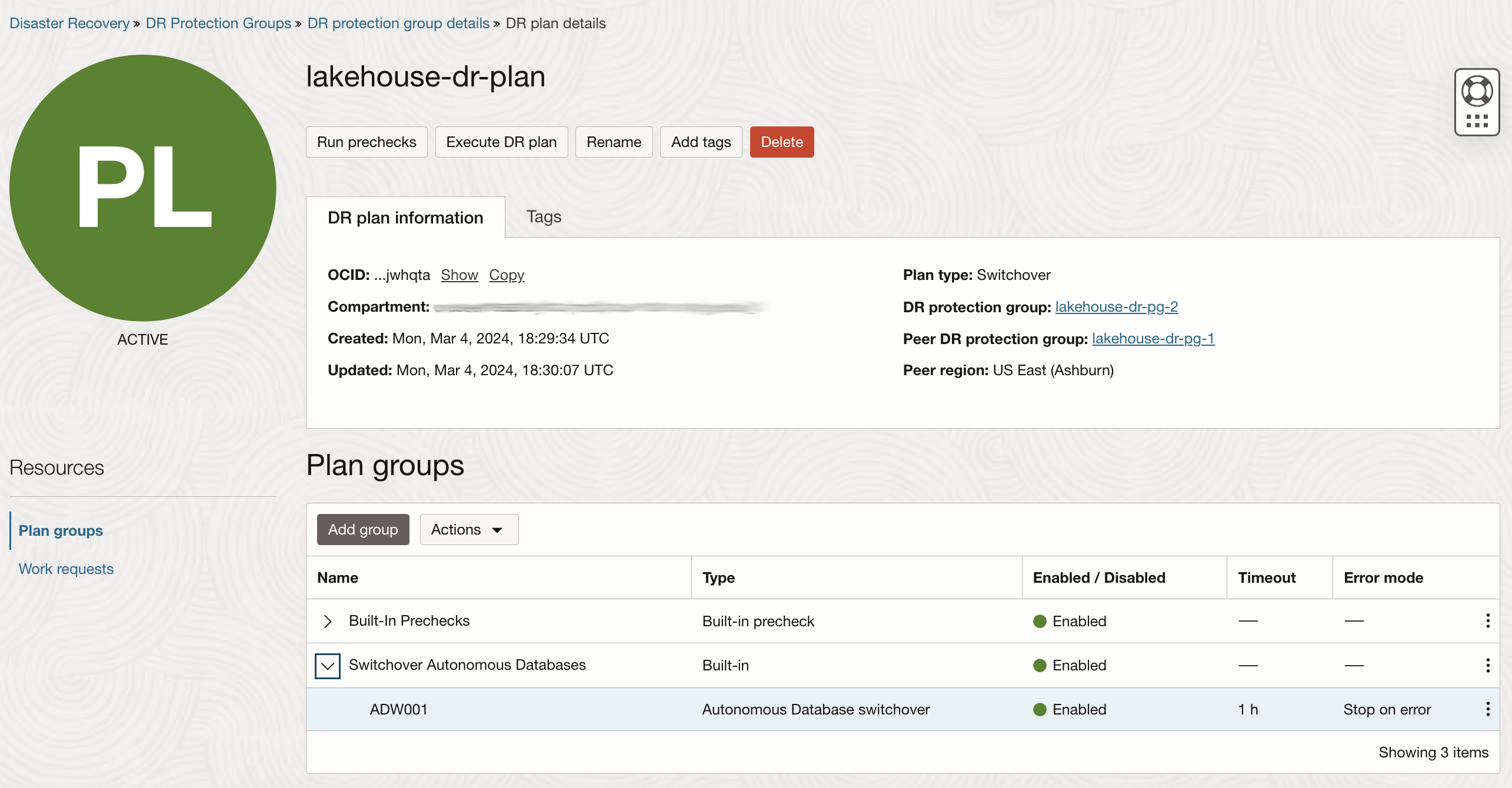
Now you can add the user-defined group (Switchover lakehouse external tables) that will start after the ADW switchover.
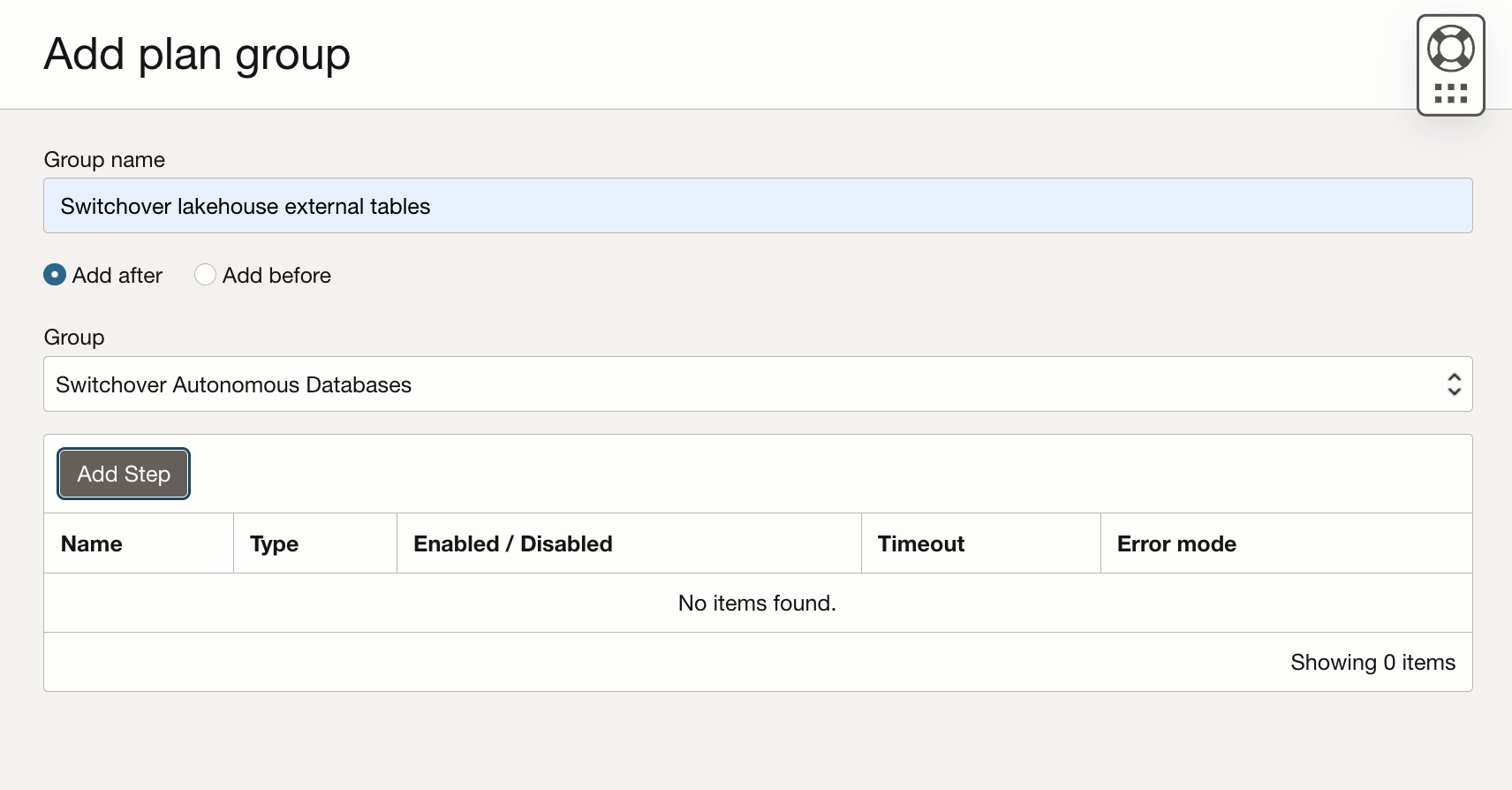
The groups will have two additional DR steps: stopping the replication policy in the target Object Storage bucket and switching the ADW synonyms:
-
make replication OS bucket writable. This step invokes the function objectstorage-make-bucket-writable-python to stop the replication policy in the target bucket (lakehouse-data-region2):
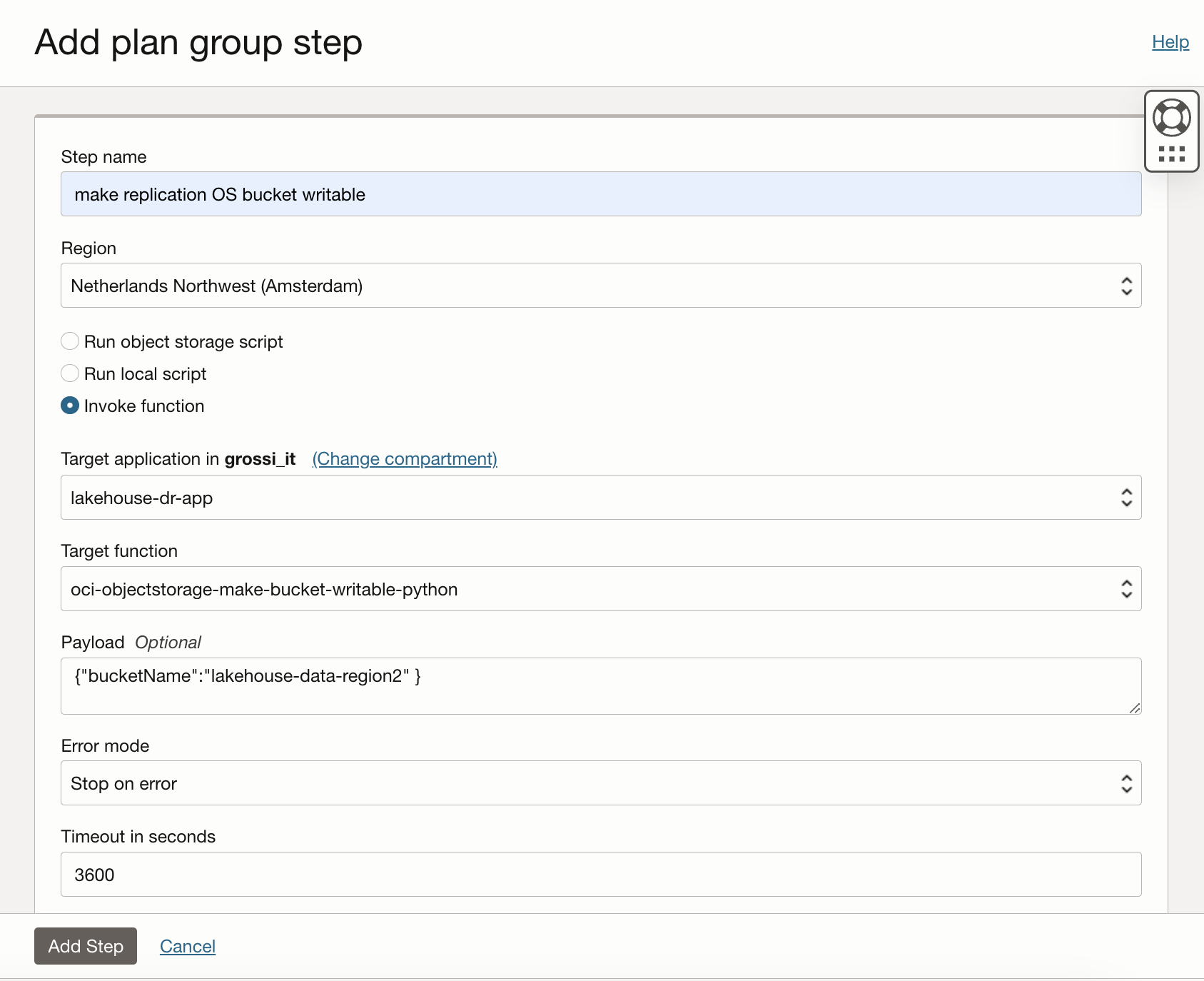
-
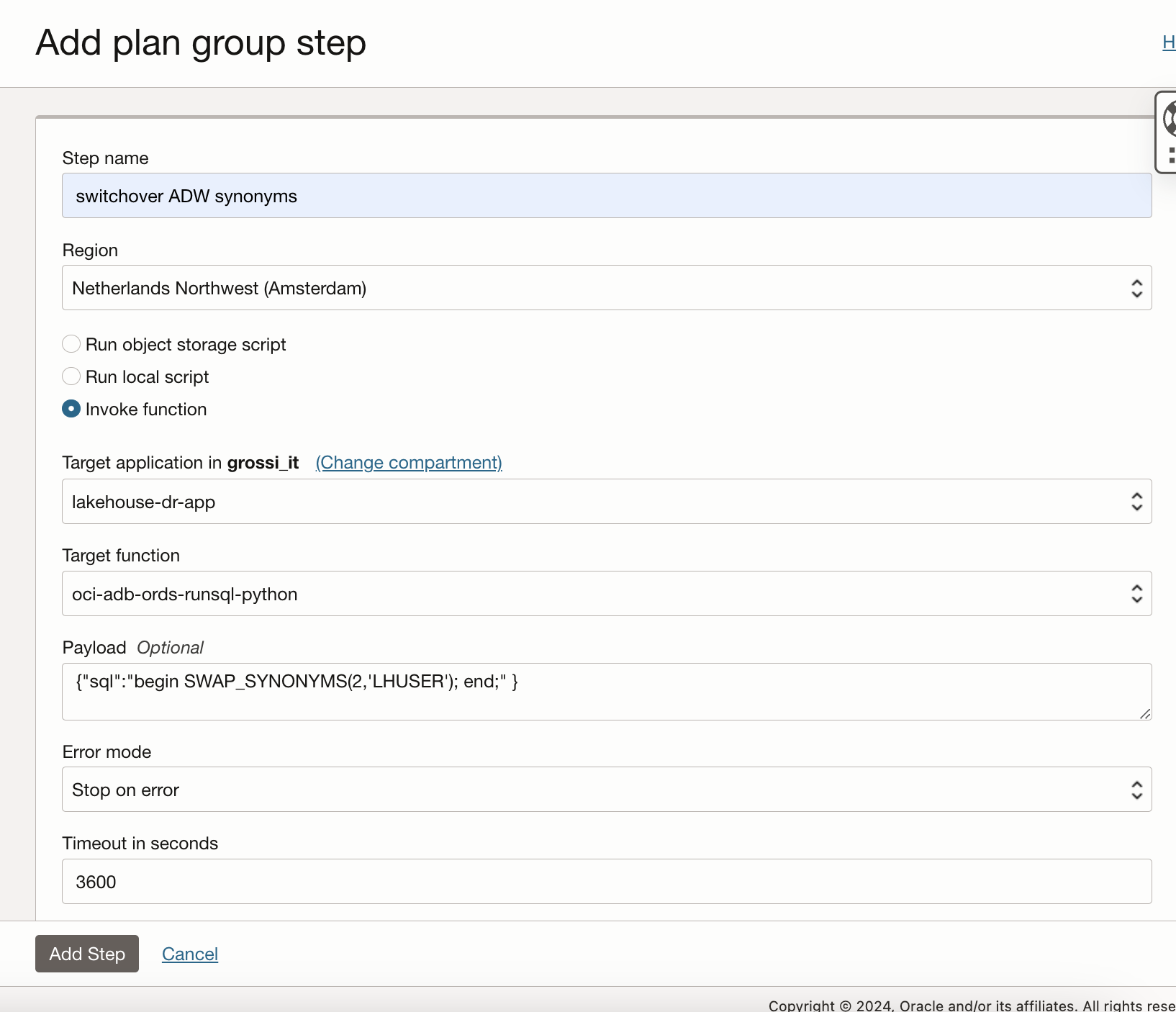
switchover ADW synonyms. This step invokes the function oci-adb-ords-runsql-python to change the suffix of the synonyms base tables. In this case the new suffix will be “2” (so for example the synonym CUSTOMER will change the base table from CUSTOMER_1 to CUSTOMER_2) for all the synonym in the DB schema LHUSER:
As final results we have a multi-region full disaster recovery plan:
Once you’ve run the pre-built prechecks group and validated the DR plan, you’re ready to switchover:
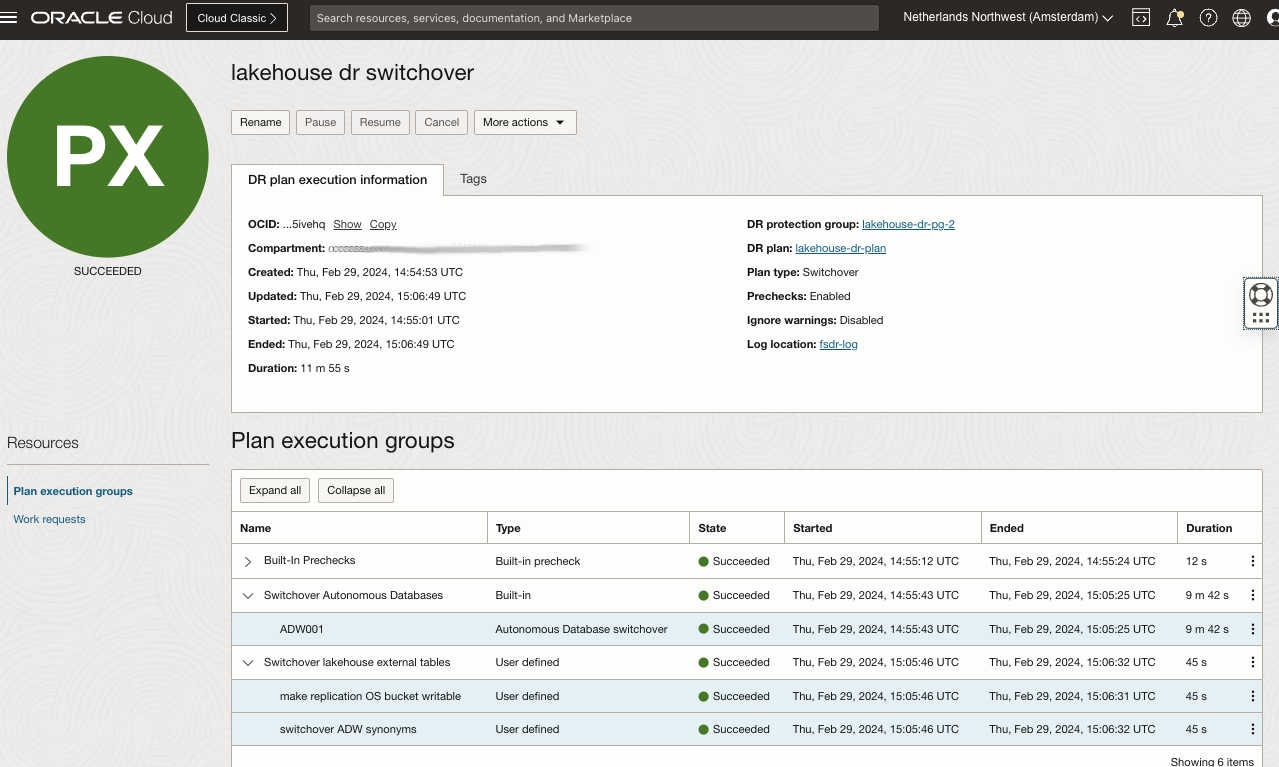
The FSDR plan completed successfully! You can see the ADW instance in Region2 (ADW001_Remote) has changed its role to Primary:
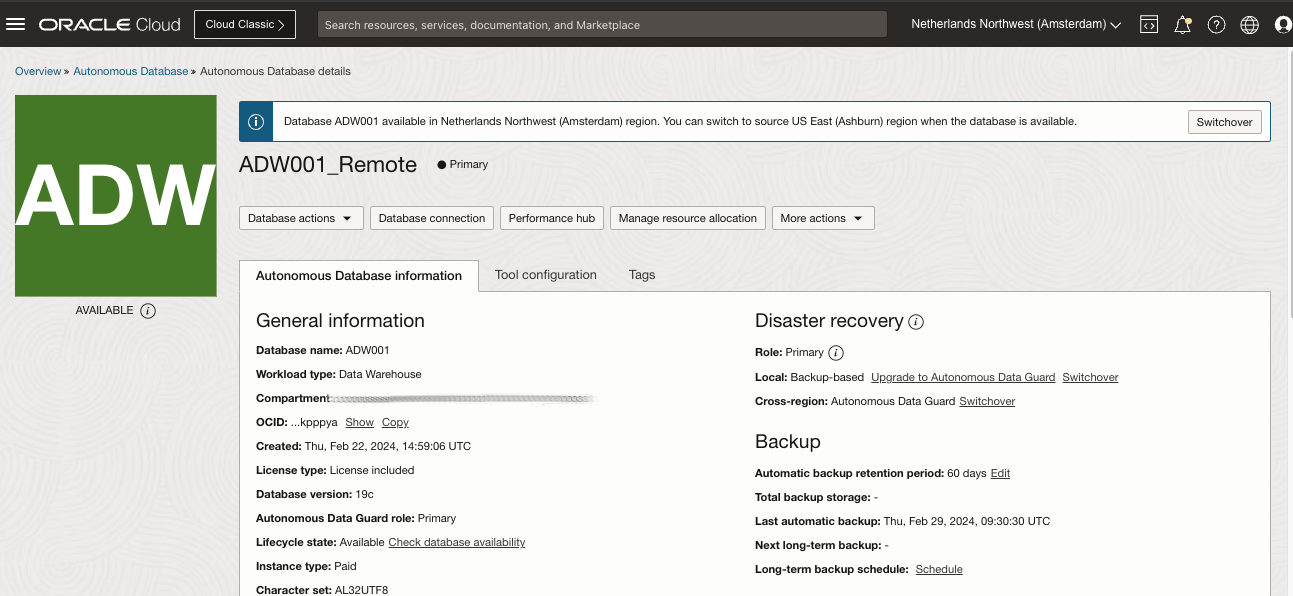
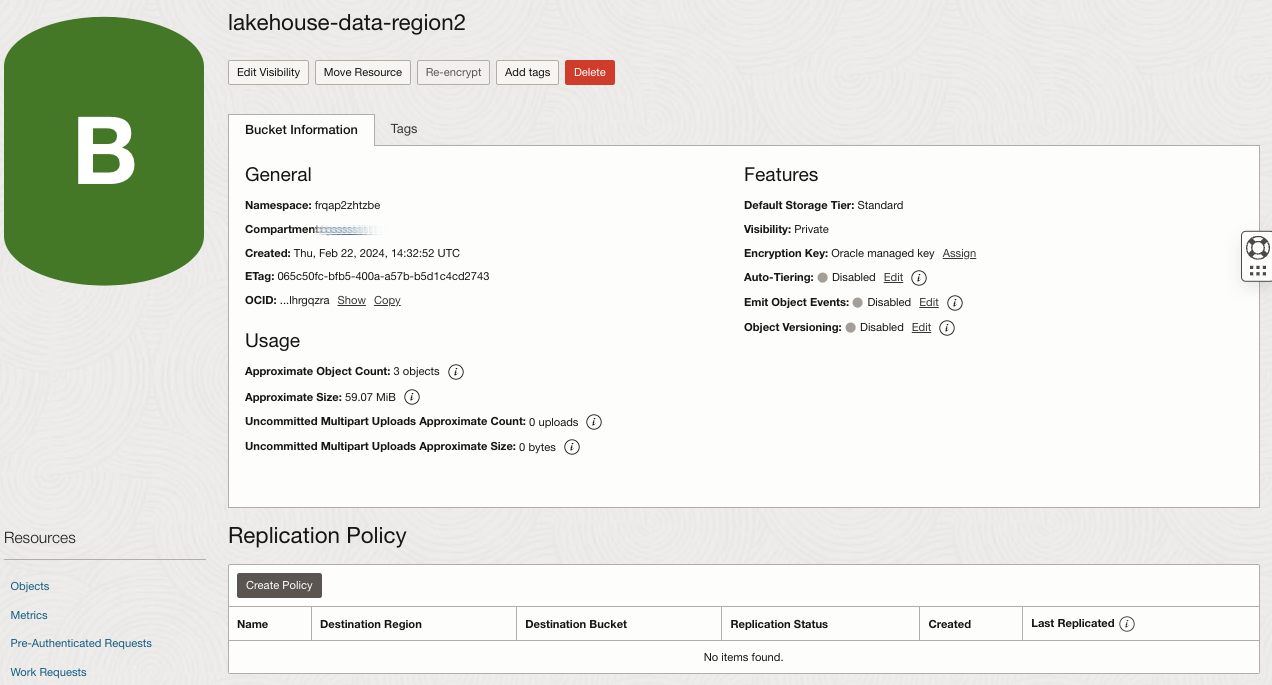
The Object Storage bucket lakehouse-data-region2 has no replication policy, and it’s become writable:
The ADW synonyms switched their base tables to the external tables with suffix _2. For example the synonym “CUSTOMER” now has CUSTOMER_2 as base table:
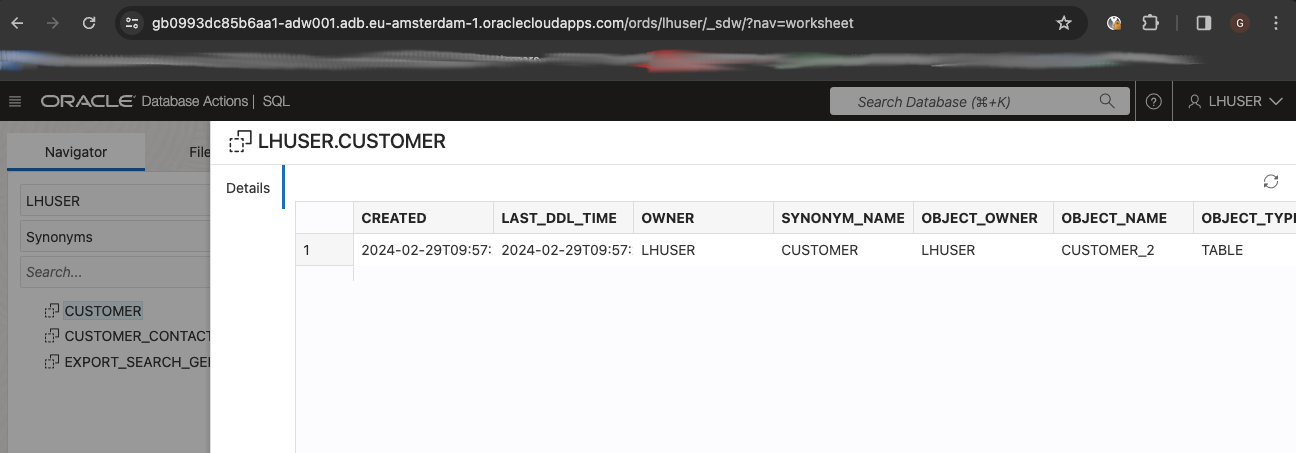
And now you can successfully query your lakehouse data:
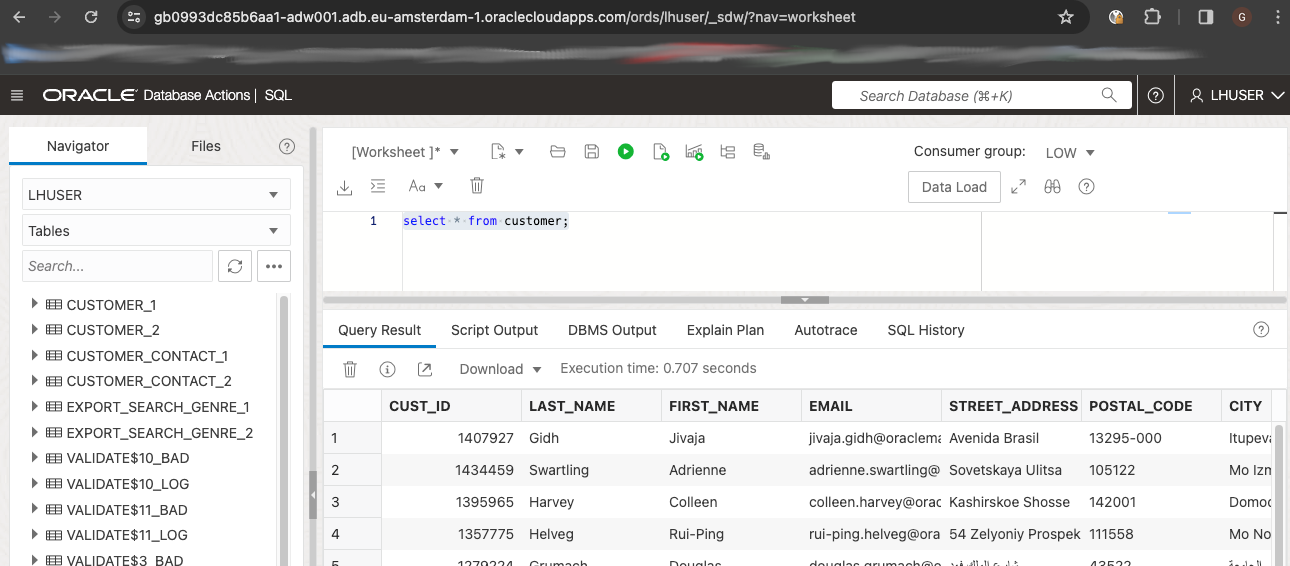
Finally, note that also the FSDR Protection Group in Region2 (lakehouse-dr-pg-2) has changed its role to Primary. Since lakehouse-dr-pg-1 is now a Standby group, you can prepare a disaster recovery plan in Region1 so that you can always switch back to these components in Region1 whenever you need (or in case of failover in Region2).
References
- OCI Data platform - data lakehouse: Oracle Architecture Center
- Oracle Autonomous Data Warehouse:
- Query External Data with Autonomous Database: Oracle Documentation
- Use Standby Databases with Autonomous Data Guard for Disaster Recovery: Oracle Documentation
- RESTful Services in Autonomous Database: Oracle Documentation
- OCI Object Storage: Object Storage Replication: Oracle Documentation
- OCI Function: Oracle Documentation
- OCI SDK For Python: Oracle Documentation
- oracle-functions-samples: Oracle Github Repository
- OCI Full Stack Disaster Recovery: Oracle Documentation
Credits
Thanks to Diego Losi, Oracle Account Cloud Engineer, for his valuable code review.