Real Time Analytics DW DR Architecture (Part I) - DR Architecture Configuration

Introduction
A disaster recovery solution is essential to prevent severe loss of data, which can have a serious financial impact and also result in loss of customer confidence, damaging a company’s reputation. As data and analytics platforms are more and more perceived as systems whose failure has those critical effects for the business, it is not uncommon that customers need a disaster recovery solution not only to meet the requirements of specific internal or external regulation but also to ensure that data consumers (including critical systems like, for instance, customer-facing applications or anti-fraud systems) can access the service without interruption, whatever may happen.
Lakehouse architecture combines the abilities of a data lake and a data warehouse to provide an innovative data platform that processes any type of data from a broad range of enterprise data resources. You can use this architecture to leverage the data for business analysis, machine learning, and data services.
As such, this architecture includes many service types that allow you to cover all the functionality and features of the data platform: upload, process, persist, analyse, and share data.
From the point of view of the Lakehouse ecosystem, a disaster recovery architecture deployment must therefore take into consideration from time to time which services must guarantee continuity in the event of a critical failure. Surely you must consider the core components of the persistence layer (i.e., Object Storage and Autonomous Data Warehouse) but you may also need to include the data ingestion and processing services (e.g.: OCI Data Integration, OCI GoldenGate, Oracle Data Integrator, OCI Data Flow) and the data access and interpretation services (e.g., Oracle Analytics Cloud, OCI Data Science, APEX and Oracle Rest Data Services) that are integral parts of the overall solution.
As a first use case, I analyze a disaster recovery solution for real time ingestion DW with OCI GoldenGate used to replicate data to a target Autonomous Data Warehouse database.
OCI GoldenGate is a fully managed, native cloud service that moves data in real-time, at scale. OCI GoldenGate processes data as it moves from one or more data management systems to target systems. You can also design, run, orchestrate, and monitor data replication tasks without having to allocate or manage any compute environments.
In this scenario, OCI GoldenGate extracts data from an Oracle DB and replicats to a target Oracle Autonomous Data Warehouse running on OCI.
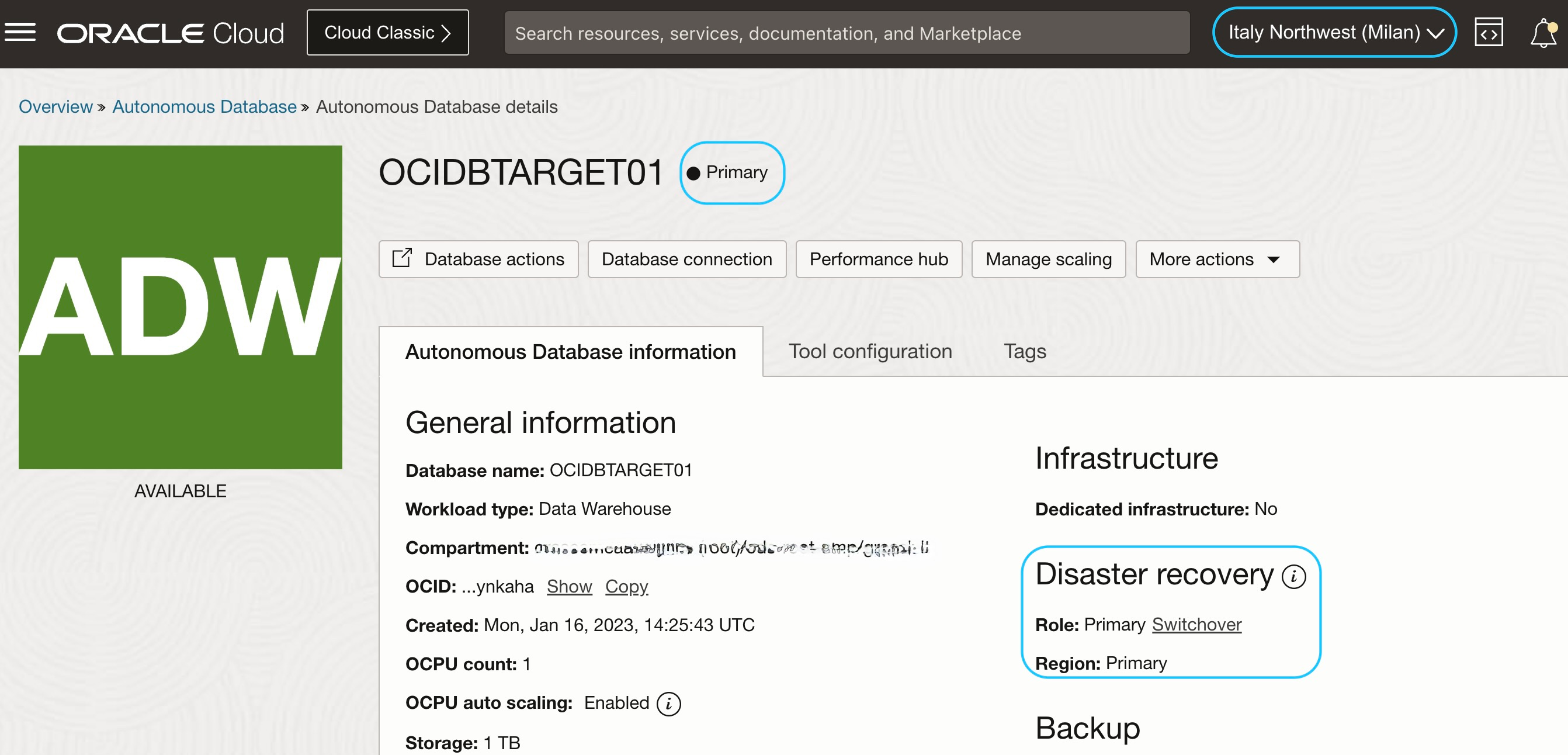
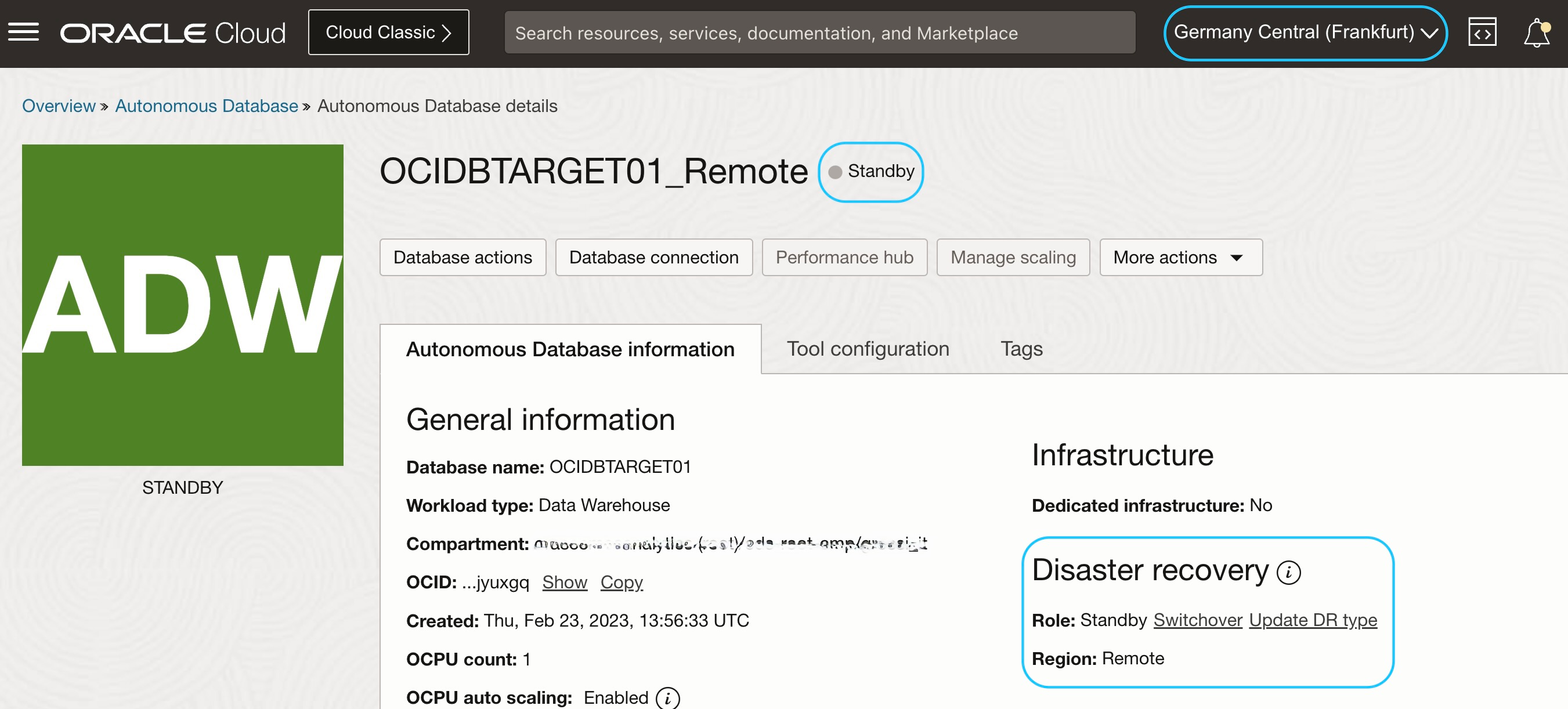
To meet Disaster Recovery requirements, another Autonomous Data Warehouse has been configured in a different OCI Region as a StandBy database, aligned by enabling Autonomous Data Guard in the primary ADW.
To provide a full Disaster Recovery solution, also OCI GoldenGate must have a deployment in the other OCI Region ready to ingest data to the Oracle StandBy Database (become Primary) whenever a disaster or a failure in the primary region occurs.
This first post shows how to enable the Disaster Recovery solution architecture for this use case. The second part of the post - Real Time Analytics DW DR Architecture (Part II) - goes through the details of the operational tasks to be executed in case of disaster.
Initial configuration: Autonomous Data Warehouse and OCI GoldenGate with single deployments
The initial configuration is similar to the one described in OCI GG Live Labs Replicate Data Using Oracle Cloud Infrastructure GoldenGate. OCI GoldenGate extracts data from an Oracle DB and moves it to a target Oracle Autonomous Data Warehouse on OCI. The Oracle DB used as a source in this example is an Oracle ATP provisioned in a different OCI Region (RegionC eu-amsterdam-1, not affected by the Disaster Recovery in this example) but, in reality, it could be any other Database, whether in OCI or on-premises.
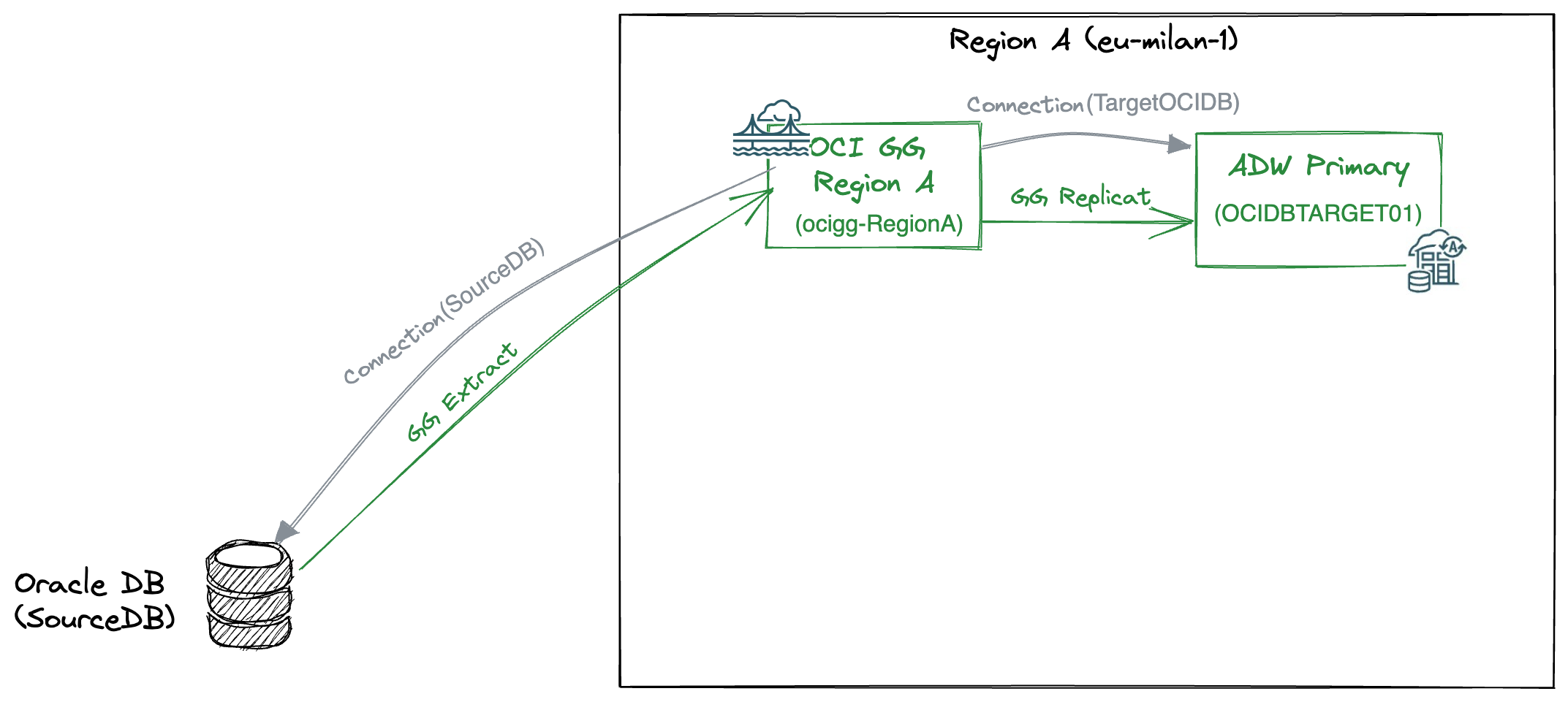
RegionA (eu-milan-01) initial configurations
1) OCI GoldenGate deployment:
- Deployment Name: ocigg-RegionA
- Assigned Connections:
- SourceDB, connection to the Oracle DB (ATP database in a different OCI Region) that has the data to be replicated to Oracle ADW in RegionA.
- TargetOCIDB, connection to the Oracle ADW database that is the target of the replicat process


- Deployment backup: Only OCI GG automatic backup
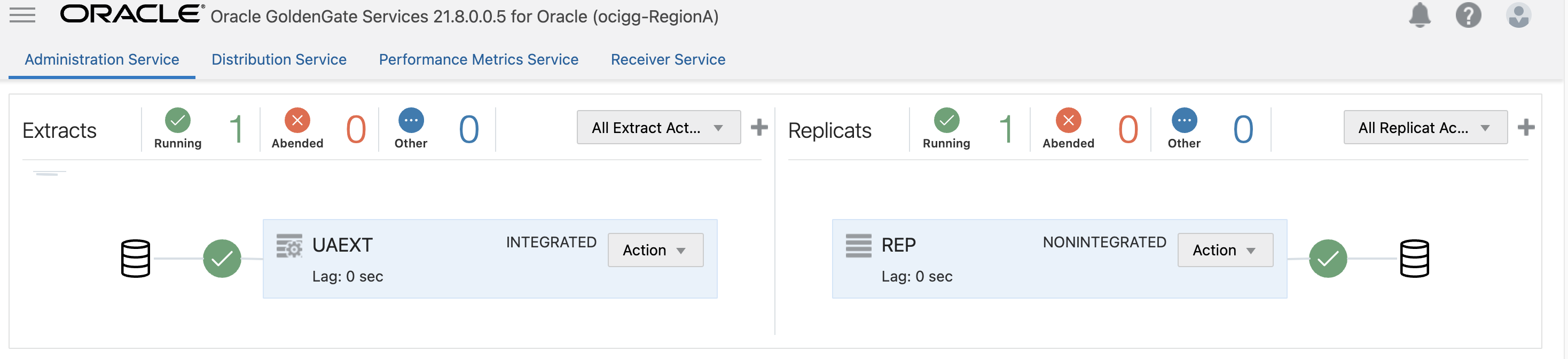
- Processes: This deployment has one extract (UAEXT) process that extracts data from the SourceDB and one replicat process (REP) that replicates the data to the TargetOCIDB.
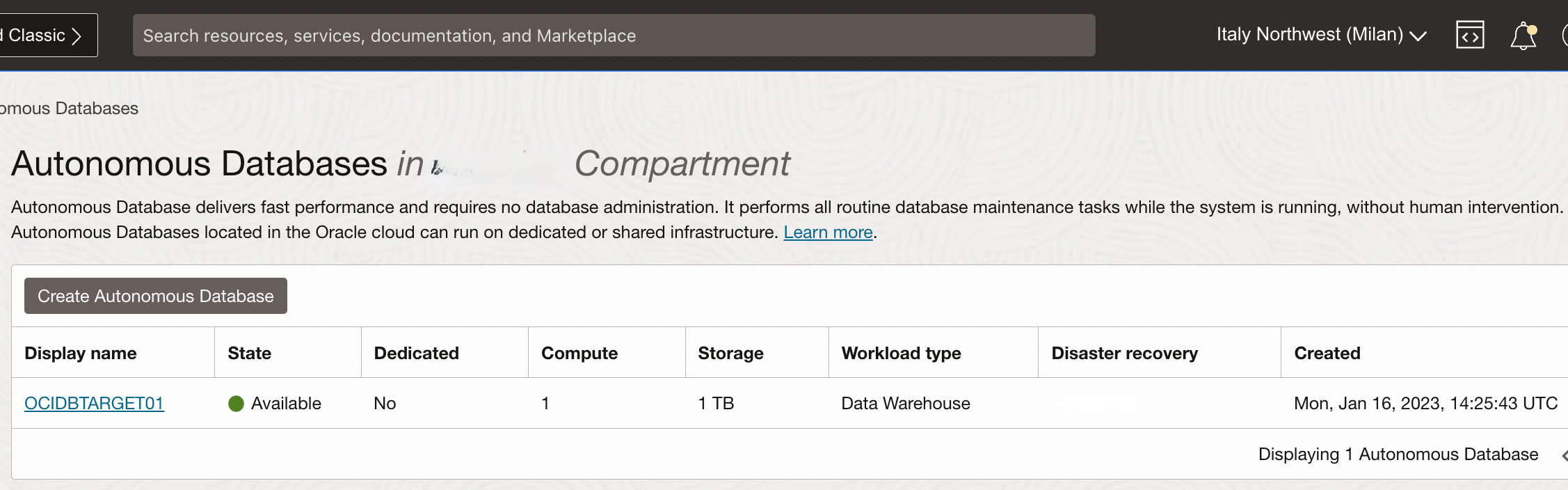
2) Autonomous Data Warehouse deployment:
- Instance Name: OCIDBTARGET01
Configuration steps to enable Disaster Recovery for Real Time DW
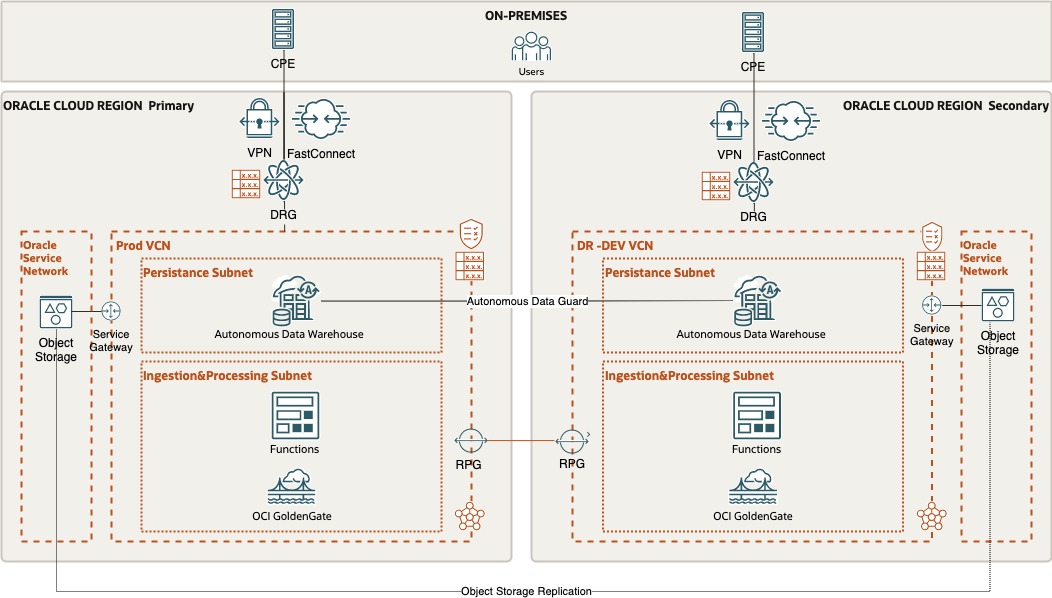
For this real-time DW architecture example, we configure a cross-Region Disaster Discovery architecture. Both ADW and OCI GoldenGate will have two deployments in two different OCI Region. The following logical architecture shows the target configurations and components for the real-time DW cross-region disaster recovery solution:
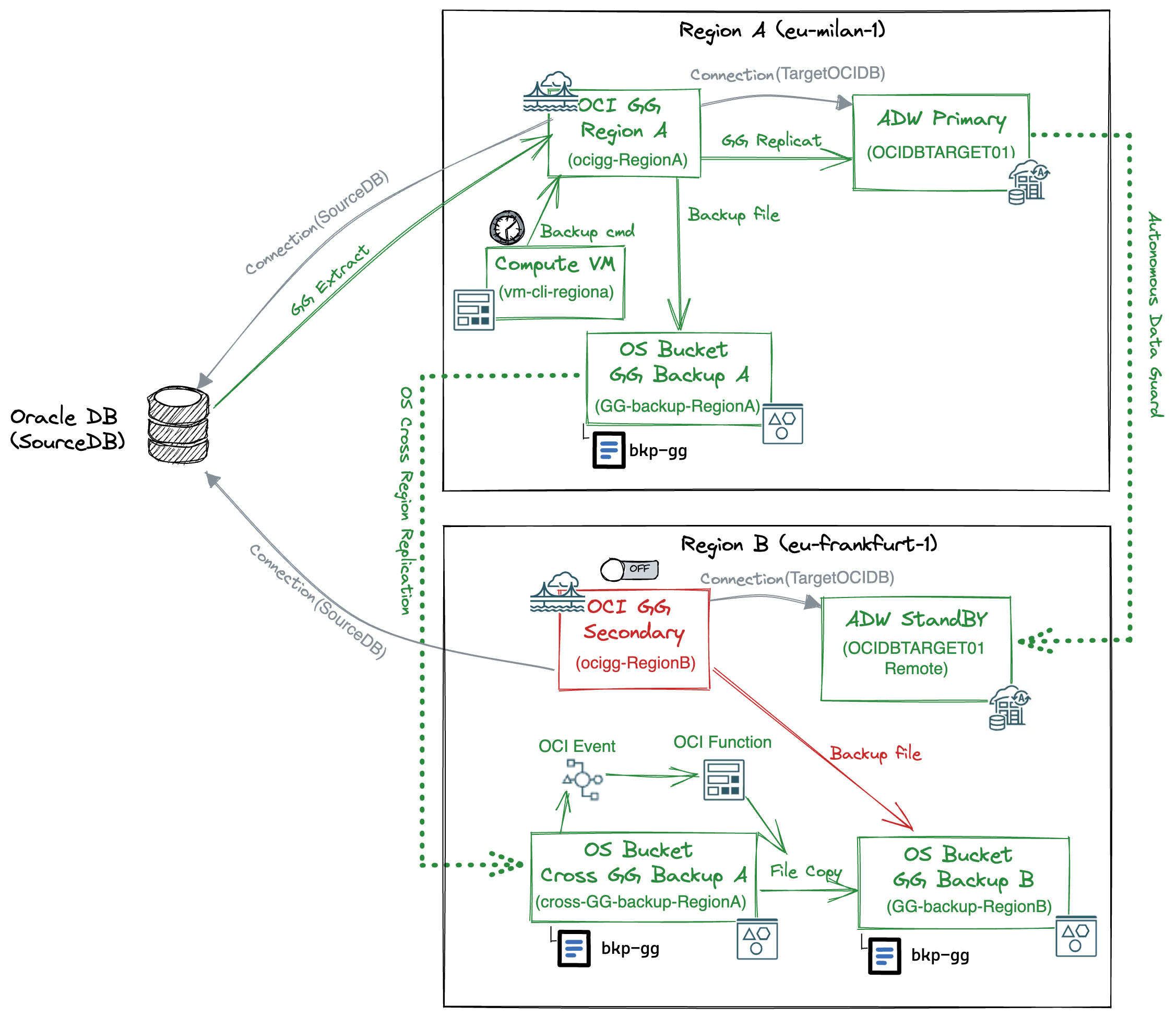
Disaster Recovery configuration for ADW
The DR configuration for ADW leverages Autonomous Data Guard. In the target Autonomous Data Warehouse database in RegionA you enable a remote “StandBy” database in another OCI Region (RegionB - eu-frankfurt-1)
- Autonomous Data Guard: enablement on the primary instance OCIDBTARGET01:
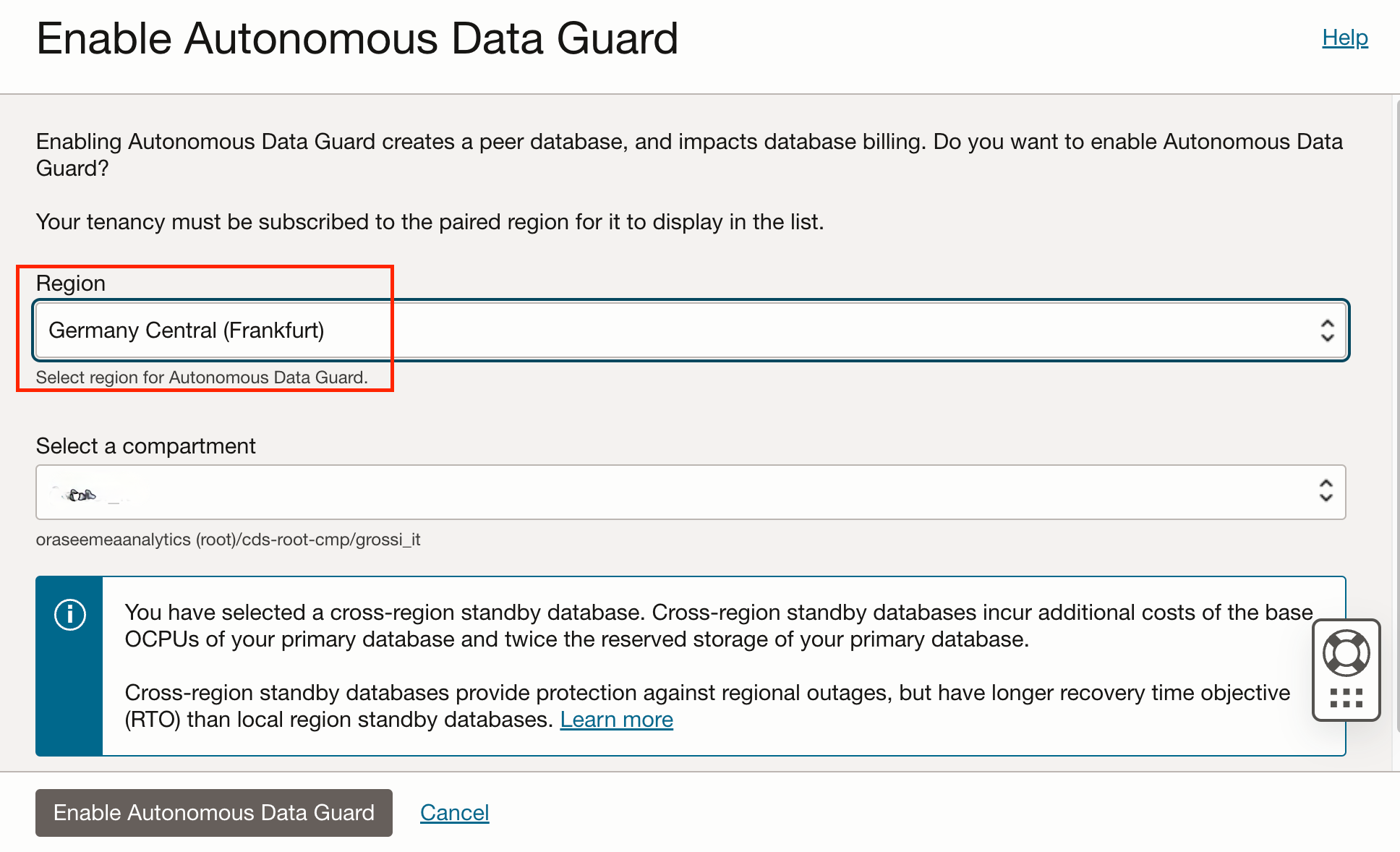
-
Remote Standby database (OCIDBTARGET01_Remote) in Region B (eu-frankfurt-1):
Disaster Recovery configuration for OCI GoldenGate
At high level, the OCI GoldenGate disaster recovery configuration leverages a cross-site replication of OCI GoldenGate backup files to share the OCI GoldenGate configuration among different deployments. OCI GG backup file stored in a ObjectStorage bucket in RegionA is replicated by OCI ObjectStorage cross-site replication to a OCI Object Storage bucket in RegionB. From there it is made available as a backup file ready to be restored by the OCI GoldenGate deployment in RegionB.
RegionA (eu-milan-01) configurations
1) Create Object Storage Bucket to store OCI GG backup files: You need to use an object storage bucket to store the OCI GG backup files to be replicated in the secondary OCI Region. You create a bucket (GG-backup-RegionA) with a standard tier.
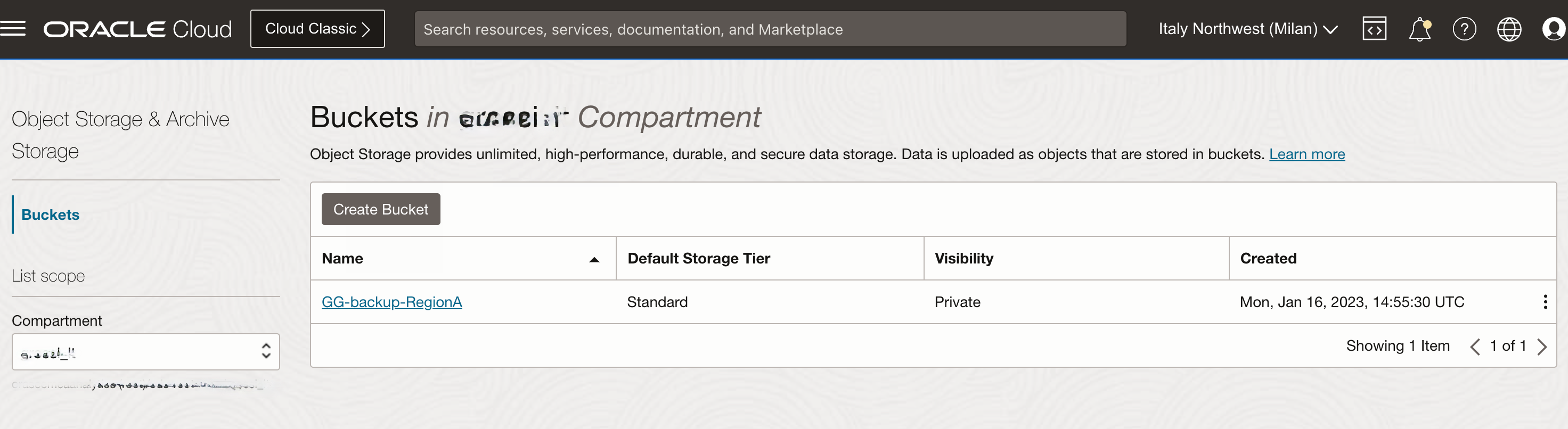
2) Enable OCI GoldenGate manual backup: the solution is based on the possibility to share OCI GG backup files between OCI GG deployments that are in different OCI Regions. As a standard, OCI GoldenGate deployments perform an automatic backup once a day. You can use those backups to restore your deployment, but you don’t have direct access to the related backup files. You need to manually create an OCI GG backup in order to be able to save and manage the related files in an Object Storage bucket. You can do it through the OCI console, API, SDK or OCI-CLI commands. You can leverage an OCI Compute VM with Linux OS in which you install the oci-cli libraries (see Oracle documentation for details) and create a script to execute the OCI GG deployment backup command.
The oci-cli command is:
oci goldengate deployment-backup create
Mandatory parameter:
-
--bucket-name [text]
(Name of the bucket where the object is to be uploaded in the object storage) -
--compartment-id, -c [text]
(The OCID of the compartment being referenced) -
--deployment-id [text]
(The OCID of the deployment being referenced) -
--display-name [text]
(An object’s Display Name. It is the name displayed in the OCI Console in the backup section of the OCI GG deployment) -
--namespace-name [text]
(Name of namespace that serves as a container for all of your buckets) -
--object-name [text]
(Name of the object to be uploaded to object storage. It’s the name of the file)
Connected to the Linux VM, you create a shell script with the oci-cli command to store the OCI GG deployment backup file bkp-ocigg in the bucket GG-backup-RegionA

Then you can schedule it with Linux crontab to be executed, for instance, every four hours:

NOTE 1: The OCI GG backup purpose is to save the configuration of the deployment. As such, you may want to schedule it less frequently, depending on the size of the backup. A good practice is also to generate a manual backup every time a configuration change is made, while maintaining the automatically scheduled backup for safety.
NOTE 2: You may want to create and share multiple backups in case one gets corrupted. To enable this, you can create different backup files with different scheduling in RegionA (e.g., bkp-ocigg1, bkp-ocigg2, bkp-ocigg3) and copy just the last one to the target bucket GG-backup-RegionA using an OCI Function (you need to modify accordingly the OCI Function example described later in this blog).
3) Enable Object Storage cross-region replication policy: You need to automatically replicate the OCI GG backup files to RegionB. You enable the Object Storage cross-region replication on the bucket GG-backup-RegionA having as a target the bucket Cross-GG-backup-RegionA previously created in RegionB. With this cross-region replication, whenever a new backup file of the ocigg-RegionA deployment is stored in the bucket GG-Backup-RegionA a corresponding file is replicated in the Cross-GG-backup-RegionA bucket in RegionB.
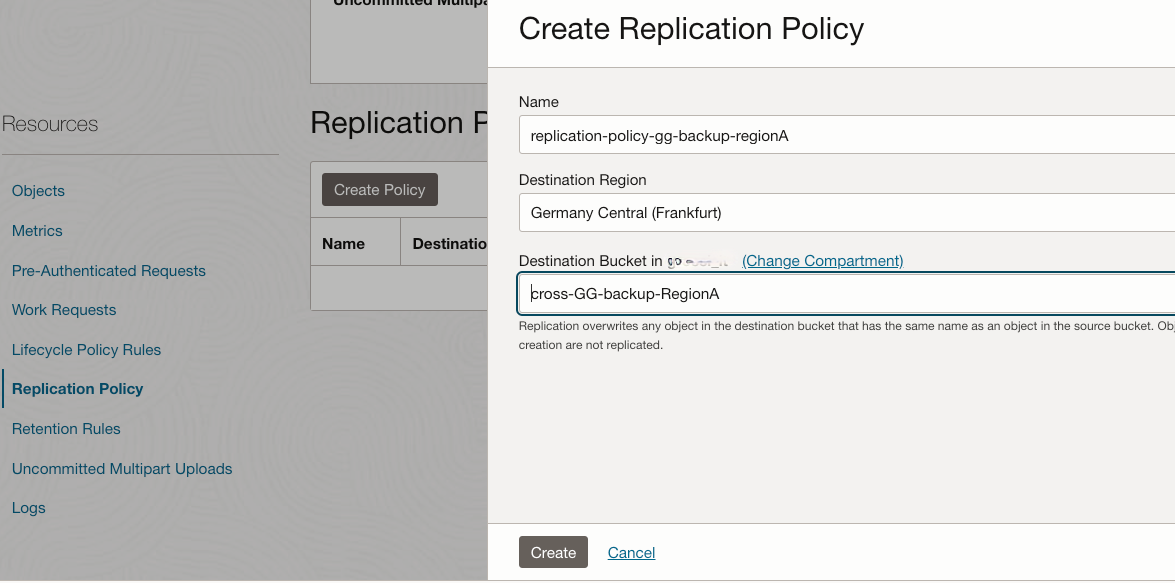
Region B (eu-frankfurt-01) configurations
1) Create OCI GoldenGate secondary deployment. It’s the OCI GG “Standby” deployment in RegionB. Initially it can be empty, with no extract or replicat process configured. In case of disaster in RegionA, it will restore the proper deployment configuration from the backup file of the of RegionA OCI GG deployment.
NOTE: Once created, to save OCI credit consumption, you may consider turning the OCI GoldenGate secondary deployment off.
- Deployment Name: ocigg-RegionB
- Assigned Connections:
- SourceDB, connection to the same Oracle DB source for RegionA (ATP database in RegionC), since it’s the source for both Regions.
- TargetOCIDB, connection to the Oracle ADW database that will be the target of the replicat process in case of disaster. The target DB is the Standby database of the ADW primary database in RegionA.


- Manual OCI GG backup: You need to create a manual backup for this deployment to produce a backup file that can be overwritten by the backup files replicated from RegionA. First, you create the bucket GG-backup-RegionB as the target bucket for backup files. Then, using the OCI Console, you can create the manual OCI GG backup (ocigg-RegionB-manual):
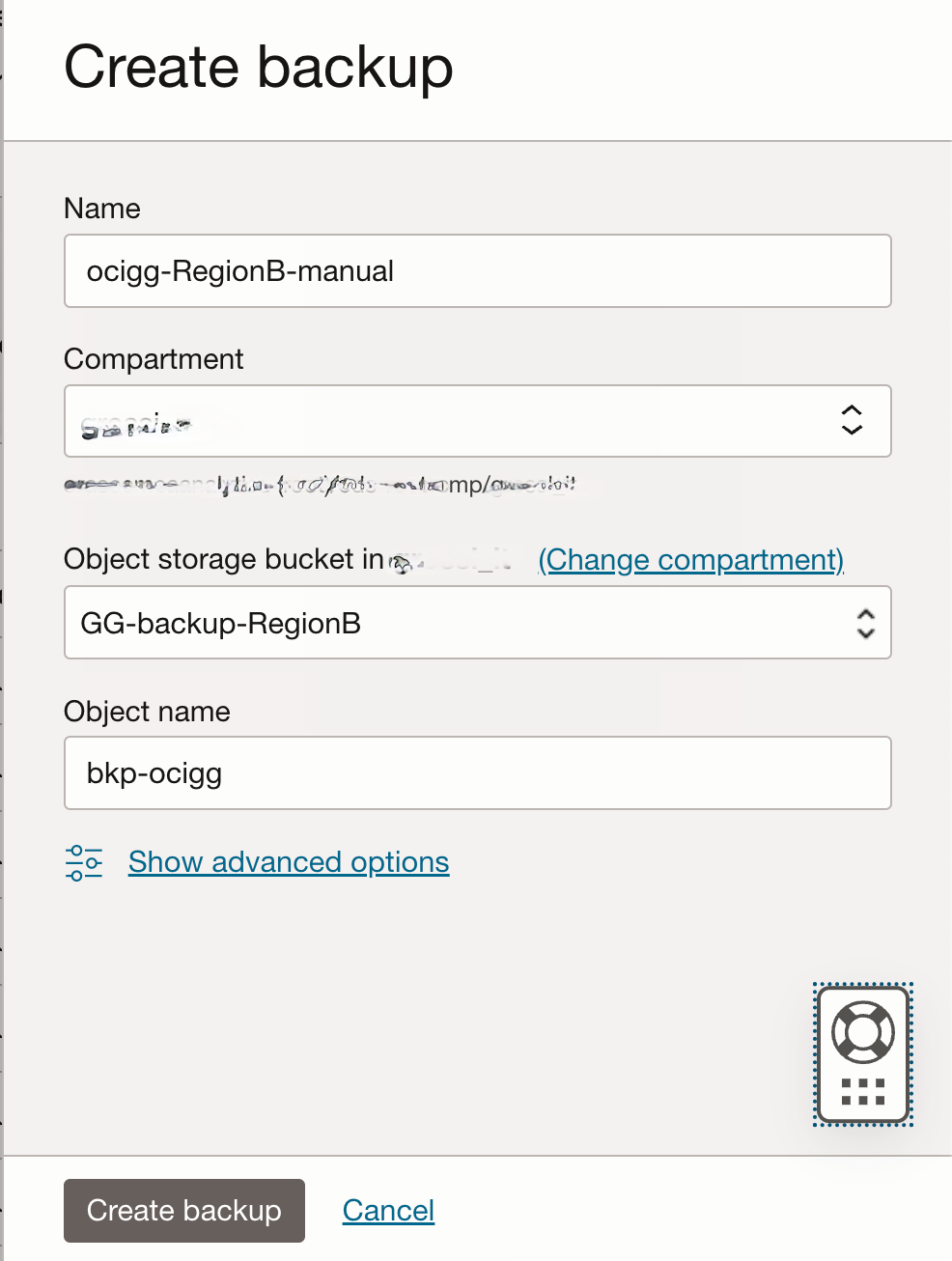
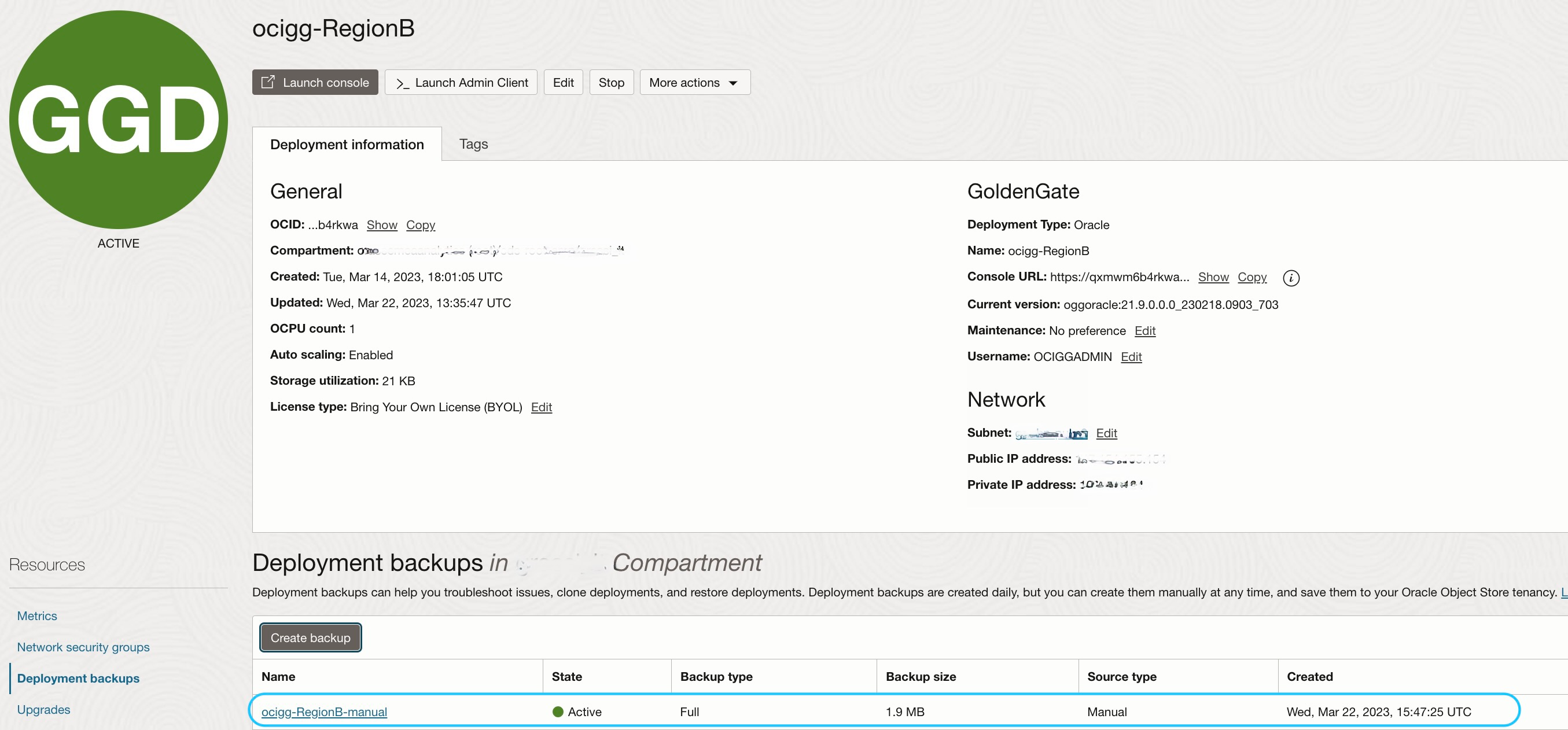
As expected the file produced by the manual backup, named bkp-ocigg, is visible in the bucket GG-backup-RegionB:
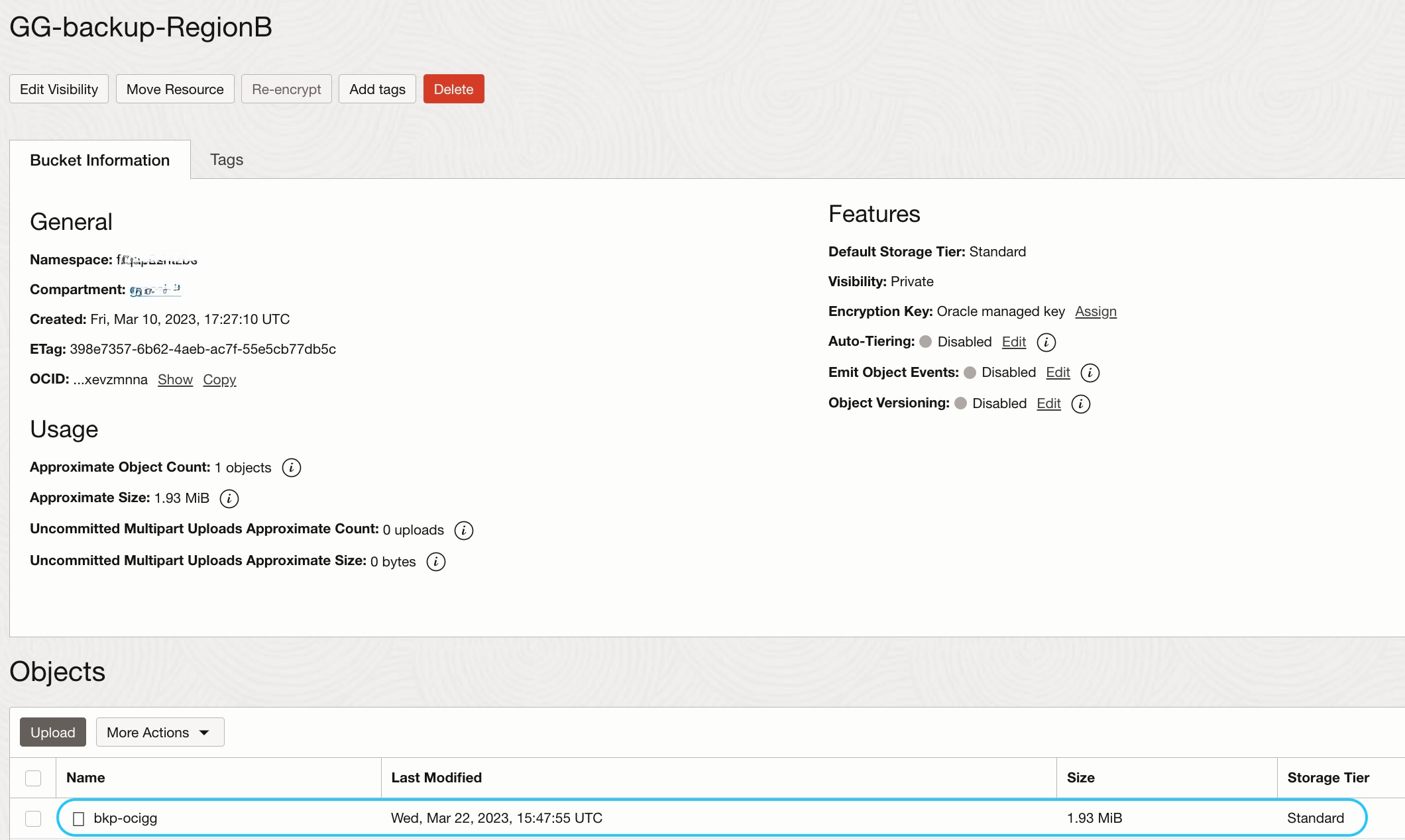
NOTE: That file can be overwritten by the OCI GG backup files replicated from the RegionA deployment.
- Processes: Initially, the OCI GG secondary deployment in RegionB does not have any extract/replicat process.

2) Create Object Storage bucket for cross-region replicat from RegionA: This bucket (cross-GG-backup-RegionA) is the target for the cross-region replicat of the bucket GG-backup-RegionA in RegionA.
3) Deploy an OCI Function to copy files to the bucket GG-backup-RegionB: To make RagionA OCI GG backup files available to the OCI GG secondary deployment in RegionB, you need to automatically copy files from the bucket cross-GG-backup-RegionA to the bucket GG-backup-RegionB. Since the files to be copied have the same name as the backup file manually created for OCI GG in RegionB, this operation will overwrite the backup file with the content of the backup files from the OCI GG deployment in RegionA.
As first step you need to create the application and deploy the Function, then you can create an Event Rule to trigger the Function when files are created or updated in the cross-GG-backup-RegionA bucket.
Create the application (a-os-replicat):
Then launch the OCI Cloud Shell and set up the fn CLI Cloud Shell:
- Set the context for RegionB:
fn use context eu-frankfurt-1
- Update the context with the function Compartment ID:
_fn update context oracle.compartment-id
- Set a unique repository name prefix (ggdr) to distinguish my function images:
fn update context registry fra.ocir.io/frqap2zhtzbe/ggdr
- Generate an Auth Token using the OCI Console
- Log into the registry using the token you just generated:
docker login -u ‘frqap2zhtzbe/oracleidentitycloudservice/myfirstname.mylastname@oracle.com’ fra.ocir.io
For details about preparing the OCI environment to deploy an OCI Function see Function Quick Start Guide.
Then you need to deploy the function. You can start from a Function example present in the Oracle Github repository (the Function oci-objectstorage-copy-objects-python):
- In the Cloud Shell clone the Github repository:
git clone https://github.com/oracle/oracle-functions-samples.git
- Then go into the samples/oci-objectstorage-copy-objects-python folder_:_
cd oracle-functions-samples/samples/oci-objectstorage-copy-objects-python
- Edit the func.py file to set the proper namespace and target bucket:
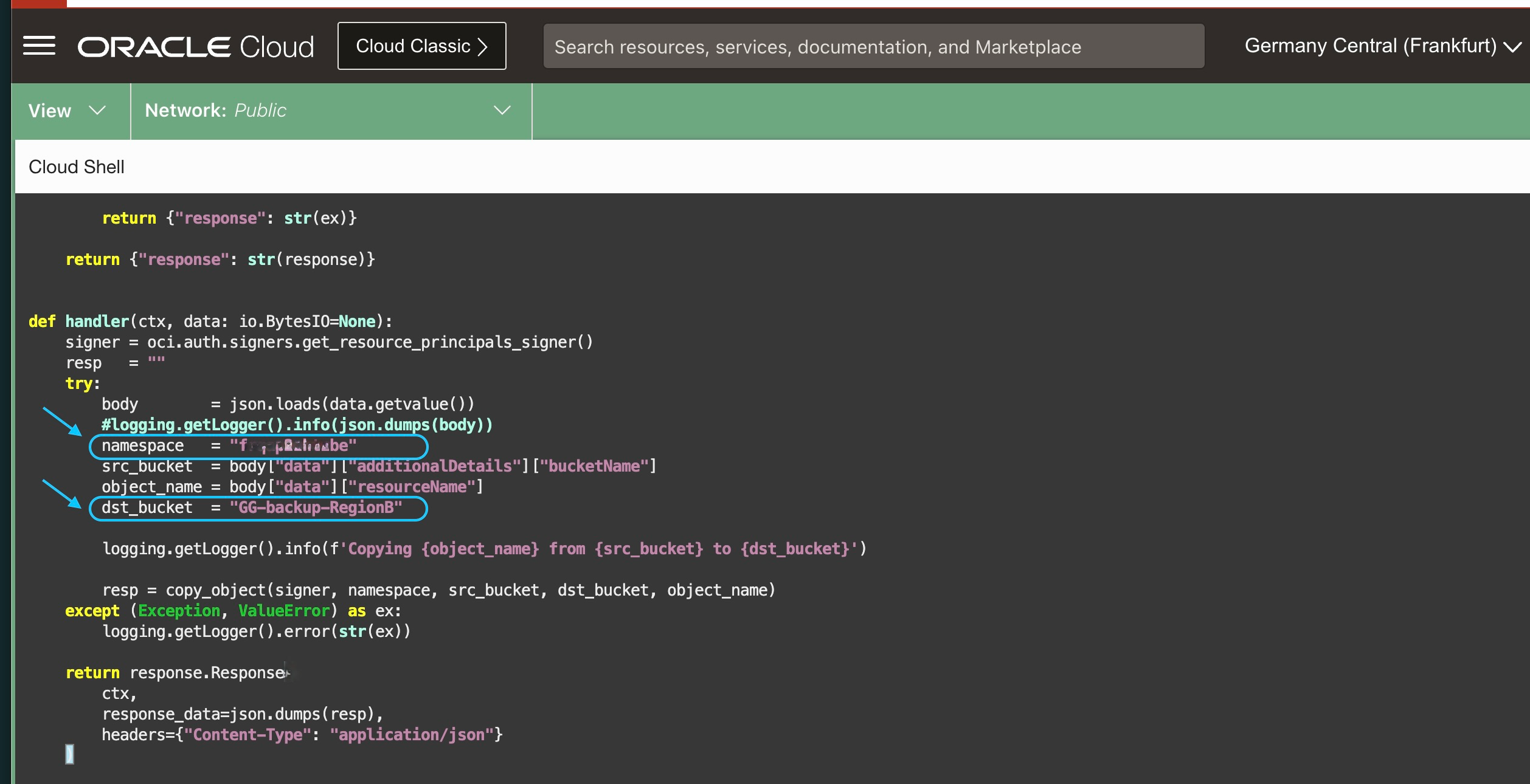
NOTE: as an alternative, instead of fixed values, you may want to configure variables for both the namespace and the destination bucket referred in the Function.
- Finally, you deploy the function in the “a-os-replicat” application:
fn -v deploy –app a-os-replicat
4) Create an Event Rule to trigger the OCI Function: You need to create an Event Service rule that triggers the OCI Function oci-objectstorage-copy-objects-python whenever an object is created or updated in the bucket cross-GG-backup-RegionA.
Create the rule e-os-file-replicat with the following conditions:
| Condition | Service/Attribute Name | Attribute Value |
|---|---|---|
| Event Type | Object Storage | Object-Create, Object-Update |
| Attribute | compartmentName | <my compartment name> |
| Attribute | bucketName | GG-backup-RegionB |
And with this action:
| Action Type | Function Compartment | Function Application | Function |
|---|---|---|---|
| Functions | <my compartment name> | a-os-replicat | oci-objectstorage-copy-objects-python |
Creation of the Event Service rule:
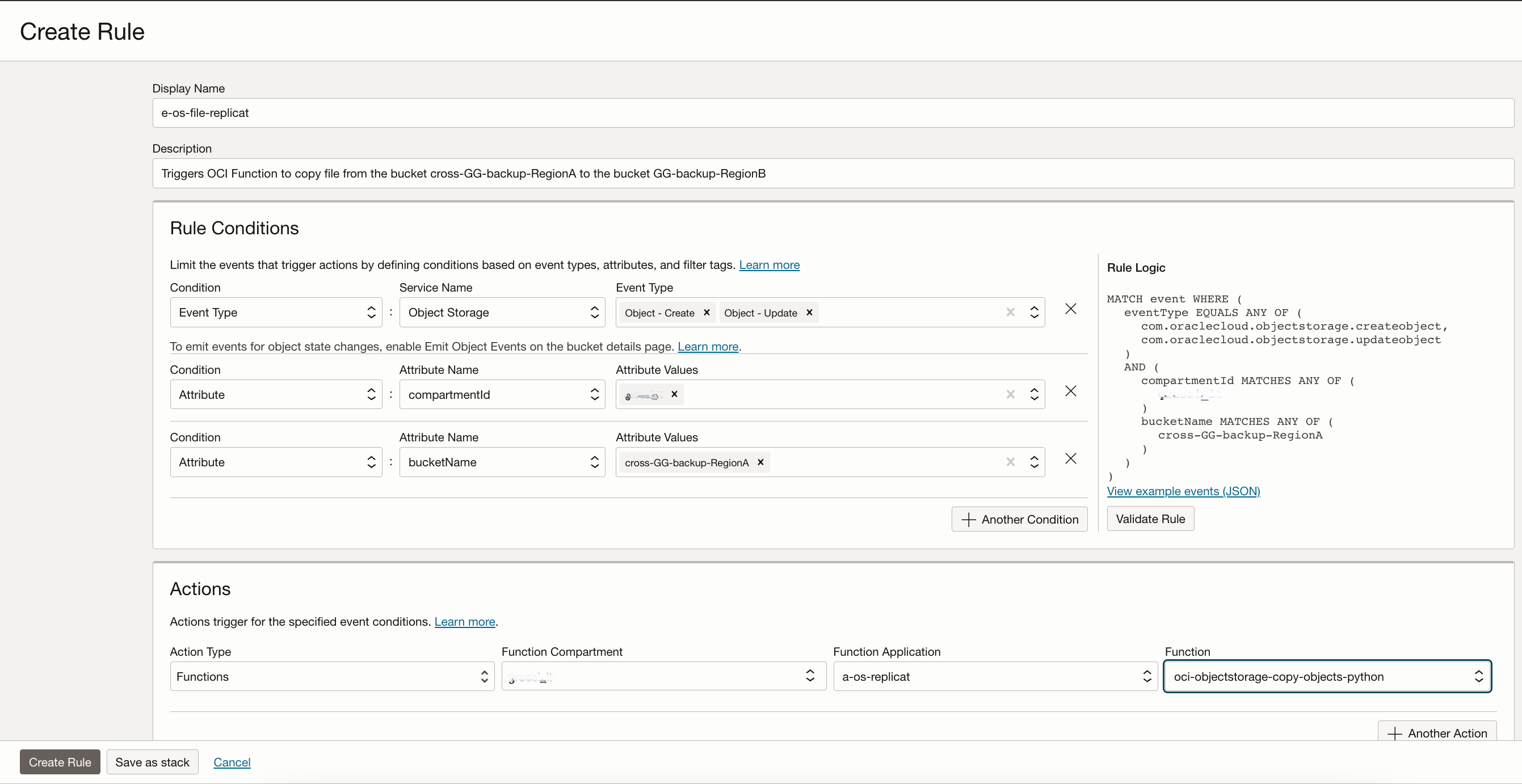
Whenever an OCI GG backup file is replicated (through Object Storage Cross-Region Replication) from the bucket GG-backup-RegionA in RegionA to the bucket cross-GG-backup-RegionA in RegionB, this rule triggers the OCI Function that copies the file in the bucket GG-backup-RegionB, ready to be restored by the OCI GG secondary deployment.
Additional Notes
Regions specular configuration
In this post, I start with the primary region (RegionA) configurations, and then I describe the secondary region (RegionB) ones. Configurations differ, but in reality, primary region and secondary region should have specular configurations because primary and secondary are only temporary concepts. A primary region can switch to secondary region, and vice versa, at any time.
Therefore you should consider to add:
In RegionB:
- A manual backup for the OCI GG deployment ready to be scheduled once the deployment becomes primary.
- An Object Storage cross-region replication to replicate the OCI GG RegionB manual backup files to RegionA. This should only be enabled after RegionB becomes primary.
In RegionA:
- An Object Storage bucket to be used as a target for cross-region replication from RegionB (e.g. a bucket named c_ross-GG-backup-RegionB)_
- An OCI Function to copy the files from the cross-region backup bucket to the bucket that stores the manual backup files (GG-backup-RegionA)
- An Event Rule that triggers the OCI Function to automatically copy the backup files from the cross-region backup bucket to the bucket GG-backup-RegionA.
The final complete target architecture looks like the picture below:
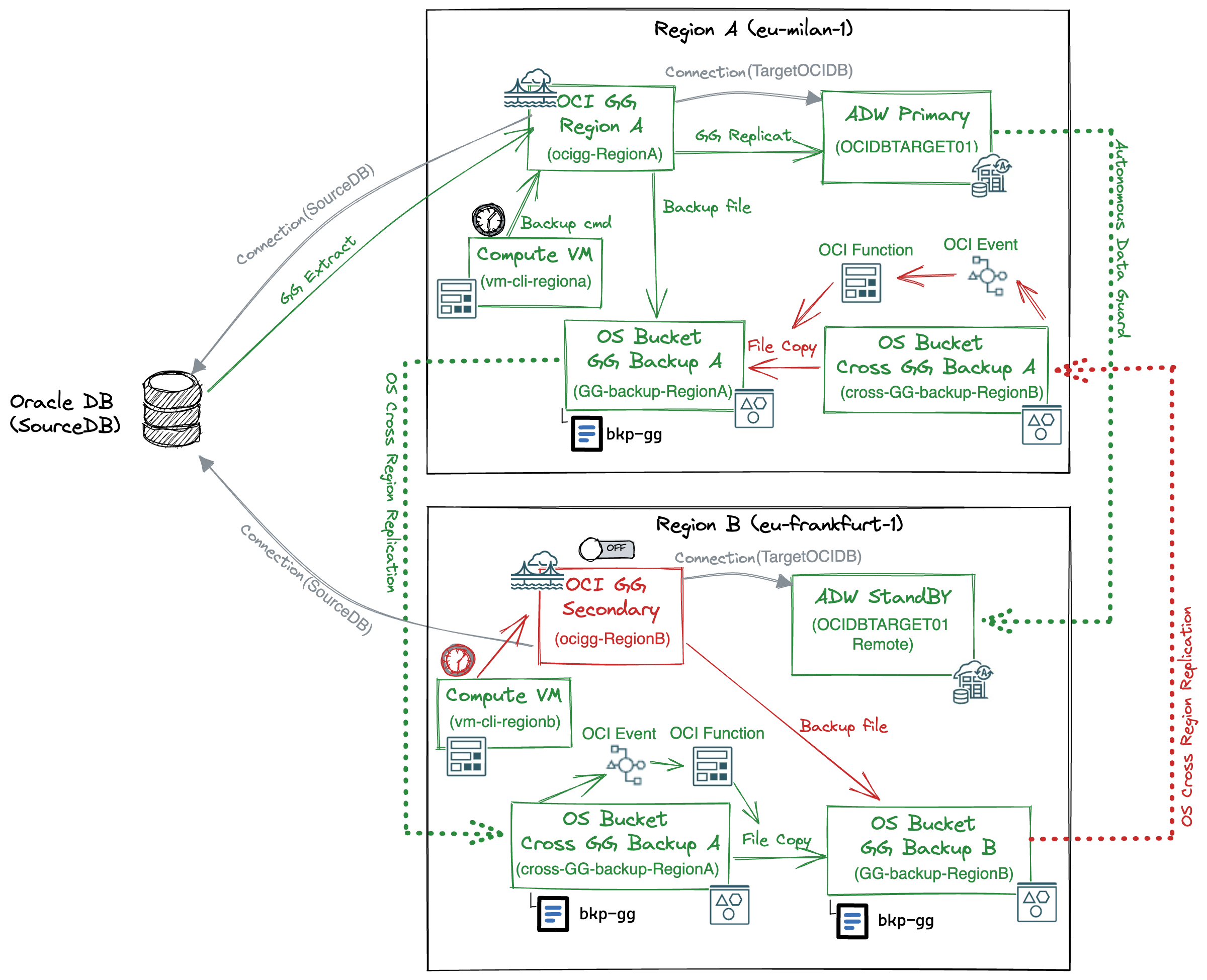
Active secondary OCI GG deployment
In this post, I suggest keeping off the secondary OCI GG deployment to save Oracle Cloud credits. But if the RTO of the solution is a priority, you may want to keep active the OCI GG secondary deployment (eventually scaled down) and automatically restore a backup file whenever a new backup is copied in the bucket GG-backup-RegionB. To do this, you need to create an OCI Function that executes an OCI GG restore and an Event Rule that triggers that Function when an object create/update event occurs on the bucket GG-backup-RegionB.
Credits
Valuable ideas, suggestions, and reviews for this post have been kindly provided by:
- Claudia Filippini, Oracle Account Cloud Engineer
- Eloi Lopez, Oracle Domain Specialist Cloud Engineer - Data Management
- Alessandro Stella, Oracle Account Cloud Engineer