Zero ETL Lakehouse in Oracle Cloud

Introduction
Who doesn’t like fruit juices?
We usually choose our favorite juices from a supermarket shelf. We know it’s not by magic. Indeed, that means that the fruits were harvested somewhere in the world some time ago, transported to the manufacturer that produces the juices, then treated during the production process, cleaned, possibly peeled, put together with other fruits according to the necessary mix, squeezed to produce the final fruit juice, mixed with other substances useful for preservation and perhaps for perfecting the taste, bottled, and finally distributed to the supermarket. Quite a long and complex process.
The results? Well, the juices are usually good, immediately enjoyable, and have a quality guaranteed by the production process, which generally requires high standards in terms of cleanliness, hygiene, health, the quality of the process itself, and the quality of the basic products. Through the label, we are informed about the validity period, we know the individual ingredients, and in many cases, we can also know which fruits they were produced with and where they came from.
Everything OK? Well, yes, since we quenched our thirst with satisfaction. But what if we start preferring a juice with a different mix of fruits and the manufacturer wants to please us? Mmmm, let’s see. He should also stock up on new fruits and add them to the production process, which perhaps should also be modified to allow for the particular processing required by the new fruits or the addition of a different additive to improve the final taste. Even if the manufacturer decides it’s worth it, we would have to wait quite some time before we could taste its version of the new juice. And what if, when we finally taste it, we don’t like it because it’s different from what we expected?
Let’s now try to imagine a different situation.
What happens if someone offers us fruit juice made from freshly picked fruit? Fruit picked at the right moment of ripeness, squeezed, and immediately drunk with the addition of just a little sugar, if we wish, would allow us to fully taste all the nuances of flavor. What incomparable freshness! Amazing!
It seems like the perfect drink to achieve maximum satisfaction. But is this different product problem-free? Some come to mind.
Have the fruits been cleaned sufficiently? Maybe yes, but no one can guarantee it, and our stomachs might only find out later…
Furthermore, it is much more difficult to have a fresh juice made with your favorite fruit mix, especially if you like blueberry, passion fruit, pineapple, and orange. Of course, we could mitigate this problem by buying fruit at the supermarket and then making the juice ourselves. It wouldn’t be the same; the fruit would still have undergone at least one transport, but a juice squeezed by ourselves could still give us more flavor (but don’t forget to reserve the time needed to do it at the moment!).
Are you wondering where I’m going?
Well, if you replace the fruits with data, an ETL process can be seen as the production process of fruit juices whose objective is to provide a final product with high quality standards, immediately usable by consumers, by first transporting and then combining and processing the basic products.
And this post aims to describe how to satisfy those who would prefer to have a juice made from freshly picked fresh fruit, reducing the time distance between collection and use as much as possible while knowing that this exposes them to potential limits on the final product.
Why ETL?
The ET-L (Extract Transform and Load) or EL-T (Extract Load and Transform) processes traditionally play a crucial role in data management solutions aimed at the creation, feeding, and management of analytic data stores.
Data extraction involves extracting data from homogeneous or heterogeneous sources; data transformation processes data by data cleaning and transforming it into a proper storage format or structure for the purposes of querying and analysis; data loading describes the insertion of data into the final target data store, typically a data warehouse, a data lake, or a lakehouse.
Conventionally, at a high level, an ETL process schema can be designed as follows:
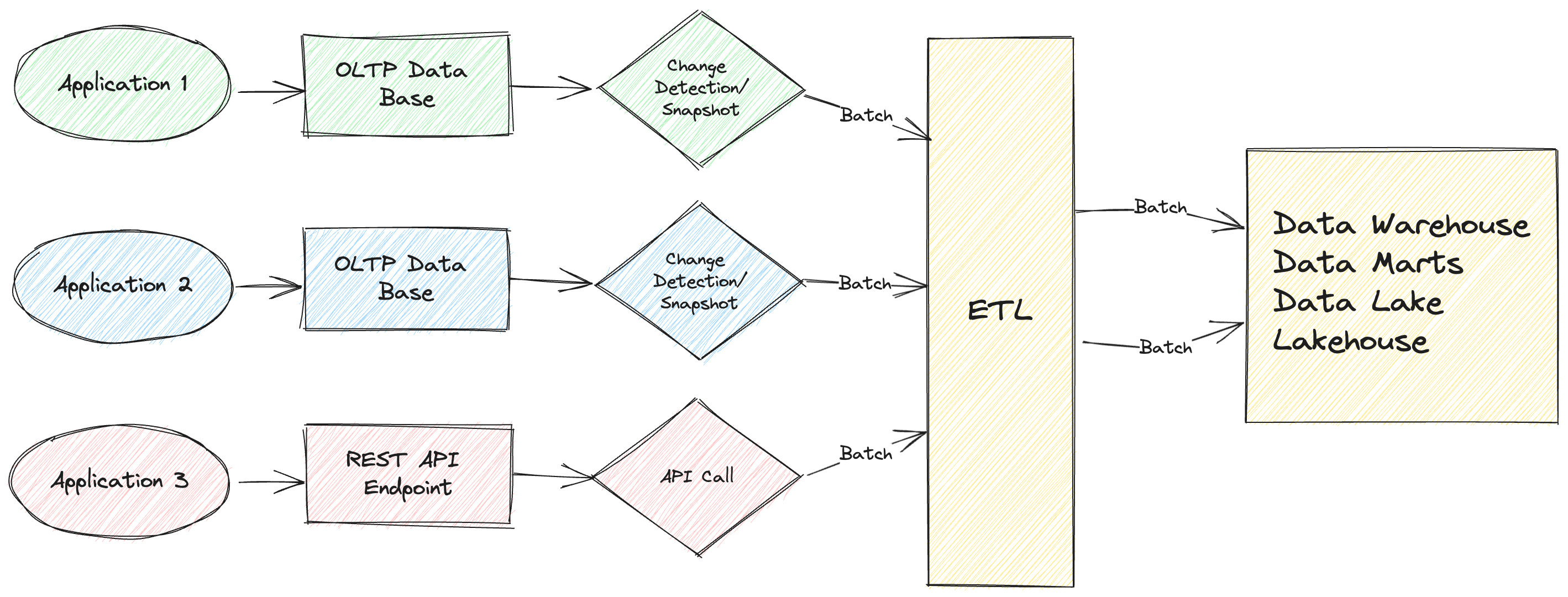
Why do we need ETL processes? Insights derived from valuable information can have a very significant impact on the success of an organization. With the exponential growth of data volume, data sources, and data types, the ability to validate, cleanse, integrate, standardize, curate, and aggregate data in well-orchestrated and governed pipelines has achieved great value in the data management processes of organizations.
But ETL, over time, has also faced us with several challenges. Here are some common drawbacks associated with the ETL process:
- Complexity: ETL processes can be complex, involving multiple steps and transformations. Designing and implementing these processes can be time-consuming, especially for large and complex data sets.
- Data Latency: ETL processes are usually scheduled to run at specific intervals (e.g., nightly batches). This means that the data in the target data store might sometimes have a latency that is not suitable for business needs.
- Maintenance Challenges: ETL processes require ongoing maintenance. As data sources change or evolve, ETL processes need to be updated accordingly. This maintenance can be complex, especially in large organizations with numerous data sources.
- Dependency on Source Systems: ETL processes depend on the structure and format of the source data. If the source systems change their data formats or schemas, it can break the ETL processes, requiring significant modifications.
- Security Concerns: ETL processes involve moving data between systems, which can raise security concerns. Ensuring data security and integrity during this process is crucial, and any breach can have severe consequences.
- Difficulty in Error Handling: ETL processes can encounter errors due to various reasons, such as network issues, data inconsistencies, or system failures. Handling errors robustly and ensuring data integrity in the face of errors can be challenging.
That’s why, in recent years, technologies such as real-time data integration and data lakes/lakehouses have been developed to address some of these limitations, providing alternatives or supplements to traditional ETL processes.
Zero ETL (or No-ETL) approach
A “Zero ETL” process is a data integration approach that aims to simplify and streamline the traditional ETL process by reducing or eliminating some of its components. The idea is to minimize the complexity of extensive ETL pipelines by leveraging different technologies (singularly or a mix of them), such as:
- Real-Time Data Integration: In a Zero ETL process, the emphasis is on real-time or near-real-time data integration. Instead of periodically extracting data from source systems, transforming it, and loading it into a data store as in traditional ETL, data is made available for analysis as soon as it’s generated or updated in source systems.
- Direct Data Access: Zero ETL often involves direct access to source systems and data streams. Through query federation or data virtualization, instead of waiting for batch ETL jobs to extract data, users can access data directly from source systems or intermediate data layers, reducing latency and providing access to the most current data.
- Data Transformation on the Fly: Rather than performing extensive data transformation as a separate step, a Zero ETL process often relies on on-the-fly transformations. This means that data transformations are applied at the time of query or analysis, reducing the need for pre-processing and data redundancy.
- Event-Driven Architecture: Many Zero ETL systems are event-driven, meaning they respond to changes in data sources as they happen. This allows for real-time data ingestion.
- In-Memory Query Accelerators: In-memory query accelerators are technologies that store and process data primarily in memory to accelerate complex queries. Many of them offer automatic integration with operational data stores, thus eliminating the need for ETL duplication.
The following sections describe the services and features of the OCI data platform that can be leveraged for designing a solution in line with a Zero ETL approach.
Zero ETL Lakehouse Architecture in OCI
Leveraging Oracle Cloud services for Analytical Data Platform, you can build Lakehouse solutions that combine the abilities of a data lake and a data warehouse to process a broad range of enterprise and streaming data for business analysis and machine learning (please visit Oracle Architecture Center for a complete description of the reference architecture).
In the context of Zero ETL, I will focus on specific capabilities and features provided by some of the services described in the reference architecture. Let’s consider the following initial state:
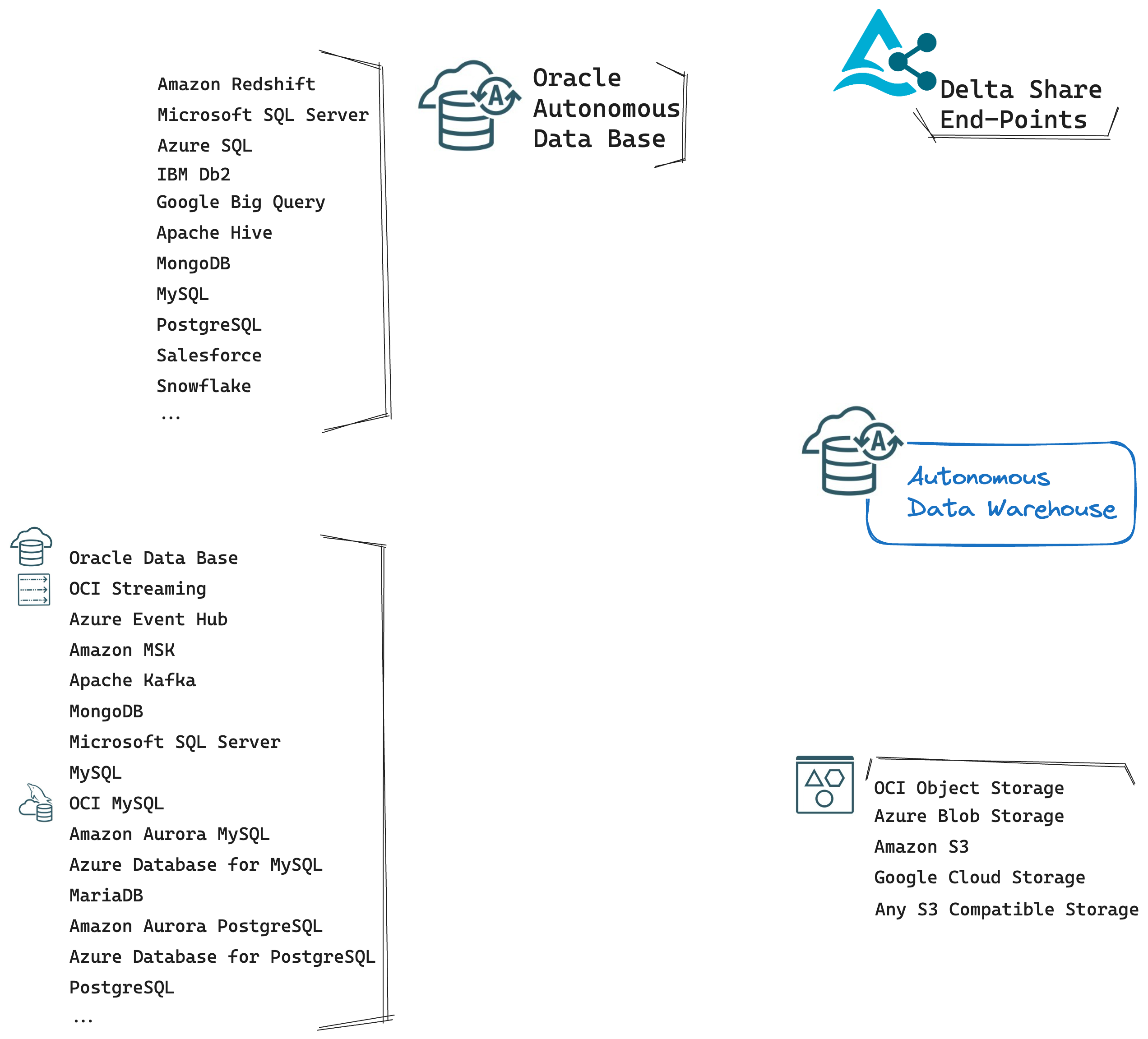
It shows many potential data sources for an OCI Analytical Data Platform that is based on Oracle Autonomous Database as a data server engine. What are the features of the OCI Data Platform that you could use to leverage those sources for your analytics needs following a Zero ETL approach?
Let’s begin with minimizing data movement and latency:
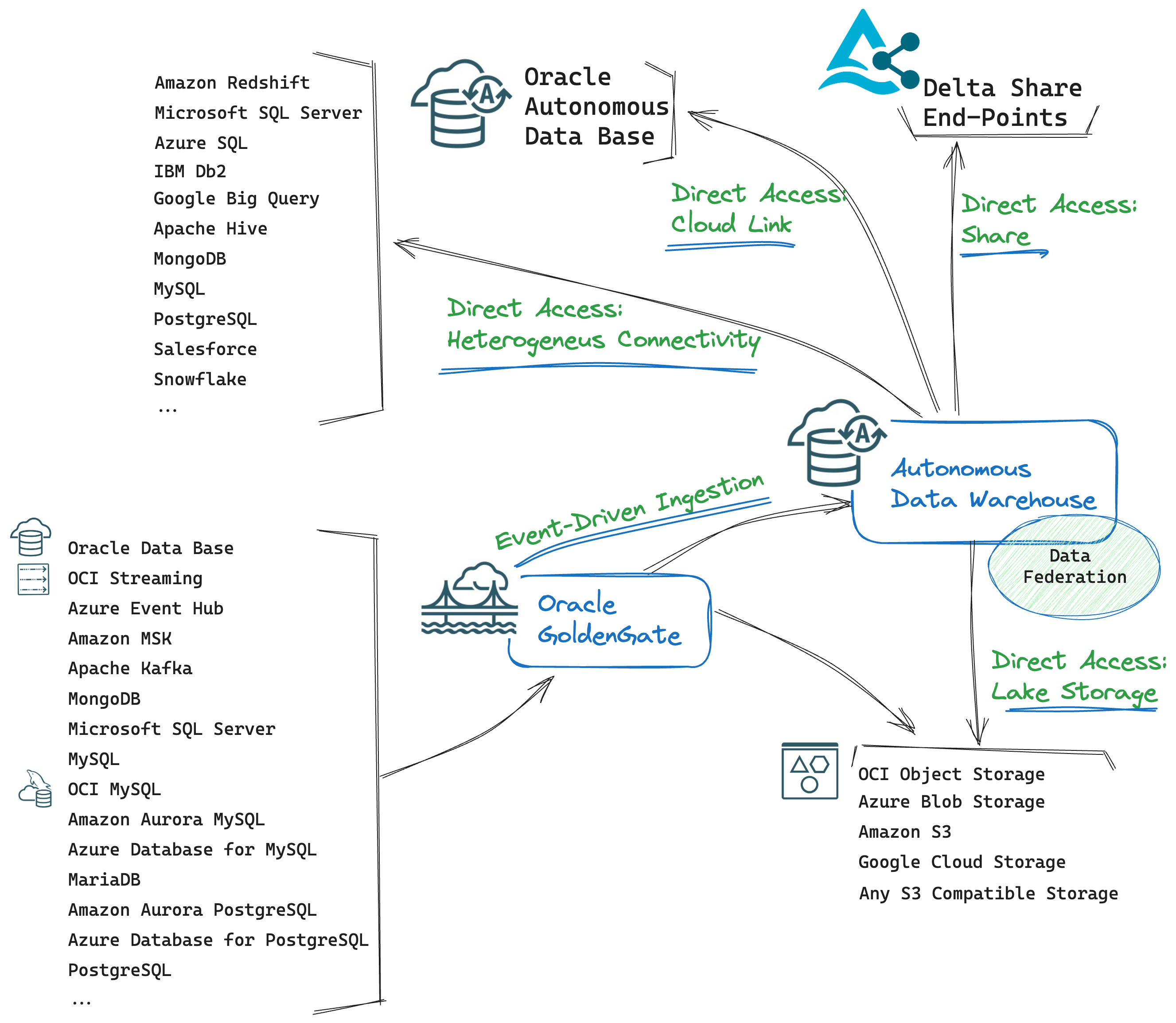
-
Direct Data Access: you can query data sources directly with:
- Oracle-Managed Heterogeneous Connectivity: allows you to easily create database links to non-Oracle databases. When you use database links with Oracle-managed heterogeneous connectivity, Autonomous Database configures and sets up the connection to the non-Oracle database. You can then leverage all the built-in analytical capabilities of Oracle Autonomous Database (machine learning, graph, spatial, pattern matching, analytic views, text analytics) to analyze data from Non-Oracle databases.
- Customer-Managed Heterogeneous Connectivity: This type of connectivity allows for the creation of database links by leveraging the Oracle Database Gateway. You can use Customer-Managed Connectivity as an alternative to link data sources that are currently not supported by Oracle-Managed Connectivity or that don’t provide compatible end-points (Oracle-Managed Connectivity, in most cases, supports only public end-points).
- Cloud Links: Cloud Links provide a cloud-based method to remotely access read-only data on an Autonomous Database instance. With Cloud Links, the data owner registers a table or view for remote access for a selected audience defined by the data owner. The data is then instantly accessible by everybody who got remote access granted at registration time. Whoever is supposed to see and access those data will be able to discover and work with the data made available to them.
- Autonomous Data Sharing: Oracle Autonomous Database supports the Delta Sharing protocol as a Data Provider and a Data Recipient, enabling secure and seamless data exchange with Oracle and external non-Oracle systems.
In addition, the OCI Lakehouse, based on the Autonomous Data Warehouse, allows users to connect to external Object Storage (OCI Object Storage, AWS S3, Azure Blob Storage, Google Cloud Storage) to directly query data stored in many different types of files (csv, AVRO, Parquet, ORC, JSON). This enables a schema-on-read approach that can highly increase the agility and flexibility of the Zero ETL solutions.
- Data Federation: We have files in Object Storage, links to objects in heterogeneous systems, different data share end-points, and we have Autonomous Data Warehouse, the engine that can query all those different sources and federate the results in a single output.
- Event-Driven Ingestion: event-driven, real-time data ingestion and processing are enabled by Oracle GoldenGate. You can capture only the changes in data sources and replicate them to the target (Autonomous Data Base or Object Storage in this case). Source and target systems are aligned in real-time, minimizing data movement and data latency.
So far, we have access to quite a complete bunch of data sources with no or minimal data latency and movement, and we can query them. That’s good. We’ve managed to minimize the Extract part, but, what about the Transform one? Let’s add some functionality to the architecture design:
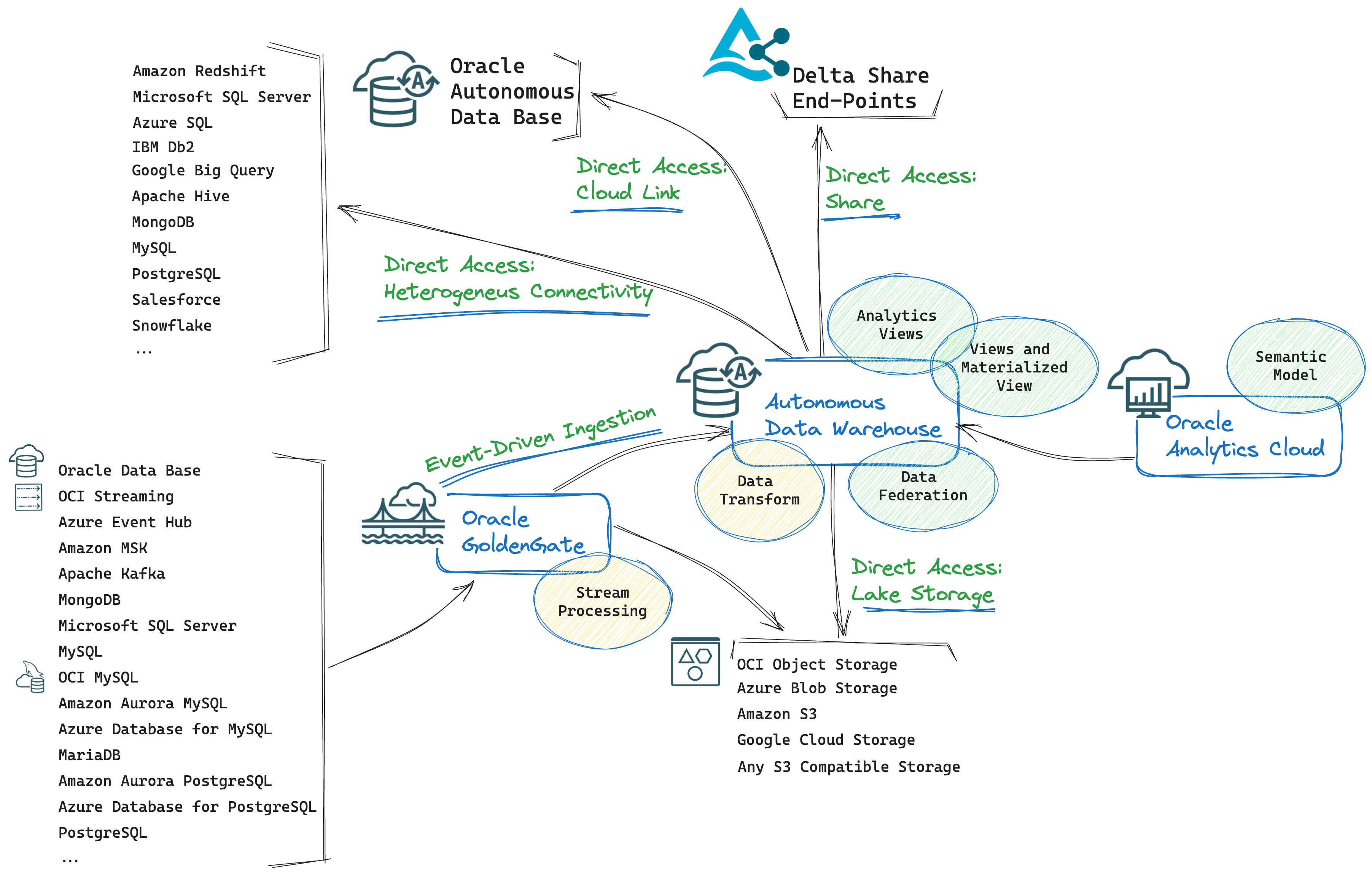
Well, we know that Transform should be minimized and on-the-fly as much as possible to please a Zero ETL approach. In that perspective, we can leverage the capabilities highlighted in the picture above, namely:
- Views and Materialized Views in Oracle Autonomous Data Warehouse: Views are particularly useful in a Zero ETL approach when you need to analyze data from different sources or different parts of your database schema, eventually performing the data integration and data transformation tasks that are often required to ease access for data consumers. You can also choose to create Materialized Views to improve query performance, especially when you need to precalculate expensive joins and aggregation operations. Clearly, Materialized Views introduce the need for a refresh, but with Oracle Database, you have multiple options to do it automatically and efficiently.
- Analytics Views in Oracle Autonomous Data Warehouse: with Autonomous Data Warehouse Studio, you can visually create Analytics Views (alternatively, you can manually create Analytics Views with the related Oracle SQL DDL statements). They are implemented as materialized views and provide a way to simplify complex SQL queries, especially those involving analytical and reporting functions, since they allow to define measures, dimensions, and hierarchies that represent the most intuitive, consolidated, and well-known modeling approach to analyze data from a business perspective. They can involve multiple tables and join them to provide a comprehensive dataset for analysis.
- Oracle Analytics Cloud Semantic Model: Oracle Analytics Cloud provides a full set of capabilities to explore and perform collaborative analytics (visualizations, dashboarding, self-service analytics, augmented analytics, self-service data preparation, and others). With OAC you can also build a semantic model. A semantic model is a metadata model that contains physical database objects that are abstracted and modified into logical objects. In a semantic model, you can create logical structures (combining and joining different physical data structures), logical calculations, and logical aggregations. A semantic model then acts like a translation layer between your logical/semantic objects and your underlying data structures.
I haven’t yet described Data Transform and Stream Processing, highlighted differently, in yellow, in the picture above. This is because they do transform and process data.
In many cases, we are dealing with a lot of heterogeneous data sources, with different update speeds, with different identifiers that identify the same data, with duplicated data, and with the quality of the basic data not controlled at the source, which also needs to be integrated with information that comes from different systems. This requires a certain degree of data transformation. That’s fine. Zero ETL is just an approach that shows a direction: minimizing data extraction and transformation. While tending to the total reduction, it suggests keeping the ETL processes as small, agile, and simple as possible.
From that perspective, if we think of the three layers of data transformation, raw, foundation, performance (also referenced in the medallion architecture as bronze, silver, gold), we should avoid performing ETL/ELT processes for the middle and final stages. To be practical, while avoiding the final steps could be an achievable goal in a good number of cases, not carrying out the typical transformations that lead to the foundation/silver layer could be more difficult or ultimately not convenient.
This is where Autonomous Data Warehouse Data Transforms for batch processing and GoldenGate Stream Analytics for stream processing come in:
- ADW Data Transforms is a complete and powerful E-LT tool embedded in the ADW system; it’s particularly suitable for our case because it does not require any data movement.
- GoldenGate Stream Analytics offers a lot of functionality to make transformation, filtering, and monitoring of streaming data very easy. It can process and analyze large-scale, real-time information by using sophisticated correlation patterns, enrichment, and machine learning. Users can explore real-time data through live charts, maps, visualizations, and graphically build streaming pipelines without any hand coding.
Conclusions
Following the Zero ETL approach, we have seen various ways in which we can directly access data and thus minimize its transport, and which tools we can exploit to carry out on-the-fly transformations, query federation, and data virtualization. And finally, a couple of options for carrying out the necessary transformations on the data, always keeping in mind the simplicity and agility of the process.
Clearly, this type of approach, while indicating the possible tools and methods that allow us to overcome some pain points of classic ETL/ELT processes, also introduces challenges to take into consideration.
Let me mention here the most immediate ones:
- Limited data integration and transformation capabilities: no, small, or on-the-fly integrations and transformations can limit solutions that by their nature or specific context, require complex transformation processes.
- Data Access Performance: views, transformations on-the-fly, query federation, and data virtualization, especially when dealing with high volumes of data, can definitely bring challenges in terms of query performance. Even if you leverage in-memory systems to run those types of tasks, you may reach, sooner or later, physical resource limits.
- Overload on Source Systems: if you query directly data sources, depending on the type of query, the number of queries, and their concurrency, you may overload data source systems that, very likely, are not supposed to serve those additional workloads.
- Data Governance complexity: query federation, data virtualization, transformations on-the-fly, and transformation embedded in semantic models make ensuring data quality and tracking data lineage more complex than using ETL tools. Indeed, ETL tools often provide these capabilities out-of-the-box or are easily integrated with enterprise-level data governance tools.
You could mitigate some of the problems by designing an architectural approach based on the definition of different data domains managed in a decentralized way. That is, an approach that shifts the responsibility for data quality and interoperability as far upstream as possible towards the data providers. But this opens a much wider chapter.
Therefore, with the assumption that it is always better to make these types of decisions with strategic direction in mind, the Zero ETL approach can certainly be evaluated as a valid substitute or, much more likely, as a supplement to the traditional ETL, carefully balancing its challenges with the benefits that it brings to the overall solution.
References
- OCI Analytical Data Platform: Oracle Architecture Center
- Oracle Autonomous Data Warehouse:
- Create Database Links to Non-Oracle Databases with Oracle-Managed Heterogeneous Connectivity: Oracle Documentation
- Create Database Links to Non-Oracle Databases with Customer-Managed Heterogeneous Connectivity: Oracle Documentation
- Autonomous Data Sharing:
- Oracle Documentation
- Delta Sharing with Oracle Cloud: Jeff Richmond’s Blog on Linkedin
- Oracle Materialized Views: Refreshing Materialized Views
- Oracle Data Transform:
- Introducing Data Transforms: Built in Data Integration for Autonomous Database: Oracle Blog
- Data Transform: Oracle Documentation
- OCI GoldenGate Stream Analytics: Oracle Documentation
- OCI GoldenGate: Oracle Documentation
- Oracle Analytics Cloud:
- Building Semantic Models in Oracle Analytics Cloud: Oracle Documentation